Xiaogang Xu (Nickname: Theo)
|
 |




Biography
I obtained my Ph.D. degree in the Department of Computer Science and Engineering at the Chinese University of Hong Kong, supervised by Prof. Jiaya Jia and Prof. Bei Yu. During Ph.D. life, I have spent wonderful times in collaborating with academics at the university (e.g., Prof. Chi-Wing Fu at CUHK, Prof. Yingcong Chen at HKUST, Prof. Hengshuang Zhao at HKU, Prof. Philip H. S. Torr at Oxford, Prof. Antonio Torralba at MIT, Prof. Christian Theobalt and Dr. Thomas Leimkuehler at Max Planck Institute for Informatics), and researchers in the industrial community (Dr. Jiangbo Lu and Dr. Nianjuan Jiang at SmartMore, Dr. Ning Xu at Adobe Research, Dr. Vibhav Vineet at Microsoft Research).
Before that, I obtained my B.E. degree in the Information Engineering at College of Information Science and Electronic Engineering, Zhejiang University.
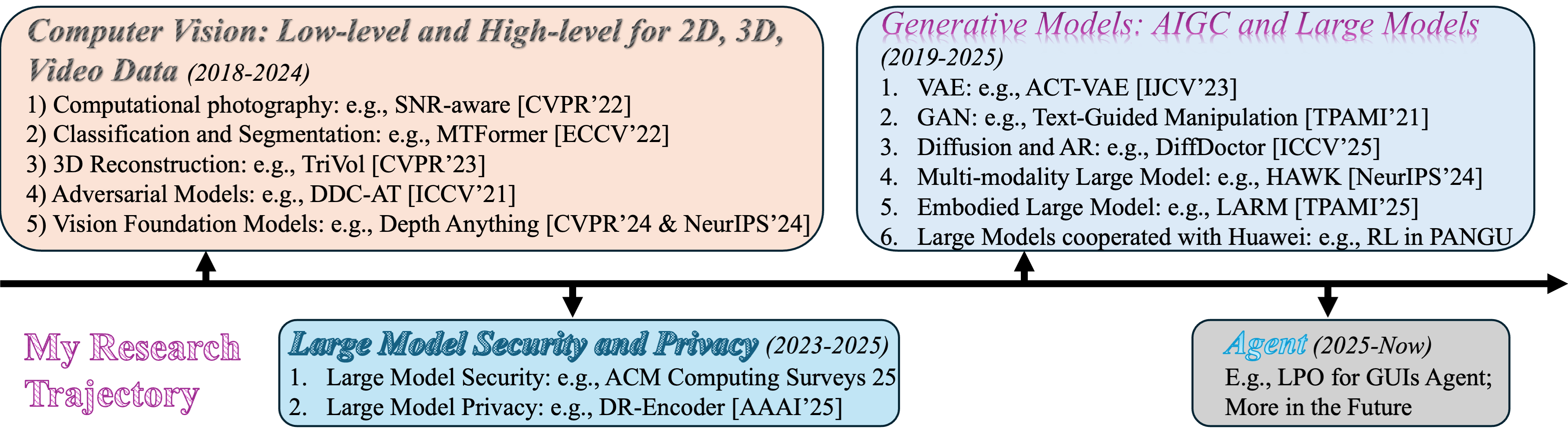
Several specific topics of our current research interests and focus:
1. Multi-modality data (image, video, 3D, etc.) generation & manipulation via AIGC;
2. Multi-modality large model and agent -> AGI;
3. Generative Computational Photography: large model and efficiency optimization;
4. Security and alignment for large models/AGI.
If you are interested in working with me, please feel free to contact me through the email.
News
- [01/2026]One paper is accepted by TIP
- [11/2025]Two papers are accepted by AAAI 2026
- [10/2025]One papers is accepted by IJCV
- [09/2025]I was selected for the list of the world's top 2% scientists.
- [09/2025]Two papers are accepted by NeurIPS 2025
- [08/2025]One papers is accepted by SIGGRAPH ASIA 2025
- [07/2025]One paper is accepted by ACM Multimedia 2025
- [07/2025]One paper is accepted by TIP
- [07/2025]Two papers are accepted by ECAI 2025
- [05/2025]Three papers are accepted by ICCV 2025
- [06/2025]One paper is accepted by ACM Computing Surveys
- [05/2025]One paper is accepted by ICCP
- [05/2025]One paper is accepted by TMM
- [05/2025]One paper is accepted by TPAMI
- [05/2025]One paper is accepted by ICML 2025
- [05/2025]One paper is accepted by IJCAI 2025
- [05/2025]One paper is accepted by SIGGRAPH 2025
- [05/2025]We release the new MLLM framework of selftok, Project page. I mainly lead the post-training stage, especially Reinforcement Learning. Its preceding work has received the Best Student Paper Honorable Mention in CVPR2025.
- [04/2025]One paper is accepted by ICMR2025
- [01/2025]One paper is accepted by ICLR2025
- [12/2024]Two papers is accepted by AAAI2025
- [11/2024]One paper is accepted by 3DV2025
- [9/2024]Two papers are accepted by NeurIPS2024
- [9/2024]One paper is accepted by EMNLP2024
- [9/2024]One paper is accepted by TVCG
- [7/2024]Three papers are accepted by ECCV2024
- [6/2024]We release the demo and code of Sagiri, which is a representative model to incorporate restoration and AIGC, especially for HDR, Project page.
- [6/2024]We release the demo and code of DepthAnything V2, which is a stronger open-world depth estimation model, Project page.
- [5/2024]We release several works about large models (Model Safety, Embodied AI, Federated LLMs, VLM)
- [4/2024]Two papers are accepted by ICML2024
- [3/2024]One paper is accepted by Transactions on Information Forensics & Security (CCF-A)
- [3/2024]In the 2024 NTIRE competition, we won fourth place in the Image Super Resolution (x4) track.
- [3/2024]Our work of virtual is incorporated into DAMO AI Platform of Alibaba
- [2/2024]Five papers are accepted by CVPR2024 (two papers are selected as Highlight)
- [1/2024]We release the demo and code of DepthAnything, Project page, Huggingface
- [12/2023]One paper is accepted by AAAI2024
- [12/2023]We release the demo and code of LucidDreamer, a excellent text-to-3D generation framework, Project page, Gradio Demo
- [09/2023]Two papers are accepted by NeurIPS2023
- [07/2023]Two papers are accepted by ICCV2023
- [05/2023]One papers are accepted by IJCV
- [04/2023]One papers are accepted by IJCAI2023
- [03/2023]Three papers are accepted by CVPR2023
- [11/2022]One paper is accepted by AAAI2023
- [07/2022]Two papers are accepted by ECCV2022
- [03/2022]One paper is accepted by CVPR2022
- [11/2021]One paper is accepted by AAAI2022
- [07/2021]Two paper are accepted by ICCV2021
- [03/2021]One paper are accepted by CVPR2021
News in 2025 (Jan - June)
News in 2024
News in 2023
News in 2022
News in 2021
Talks & Presentations
-
Give a talk in HKU with topic of "Generative Multimodal Models: Understanding, Generation, and Unification".July 2025.
-
Give a talk in Valse 2025.June 2025.
-
Give a talk in Xidian University with the topic of "From LLM to MLLM".May 2025.
-
Give a talk in Southeast University with the topic of "AIGC-based Image Restoration".Oct. 2024.
-
Give a talk in Zhejiang Lab with the topic of "Improve Model Robustness under Extreme Dark Environments".Sep. 2024.
-
Co-host a workshop in ChinaSys with the topic of "AI System Building for Large Models".June. 2024.
-
Give a talk at Nanjing University of Aeronautics and Astronautics about "Transferrable Adversarial Attacks" .June. 2024.
-
Oral presentation about future media technology at Huawei STW conference (Shenzhen).May. 2024.
-
Invited poster presentation at VALSE2024 on "Boosting Image Restoration via Priors from Pre-trained Models".May. 2024.
-
Invited talk at China3DV with the topic of "Efficient 3D Modeling for Data with Real-world Degradations".Apr. 2024.
-
Give a talk at Nankai University with the topic of "AIGC for Computational Photography in the RAW Domain" .Apr. 2024.
-
Invited talk to Responsible AI team at ByteDance, on "Responsible LLM and AIGC".Apr. 2024.
-
Selected into "Young Talent Nurturing Project at Zhejiang Lab (之江青年人才托举)" for Large Models (大模型).Mar. 2024.
-
Organizer at GAMES Webinar on "Multi-view Synthesis and 3D Shape Completion via Diffusion Models", [News].Mar. 2024.
-
Presentation at [Shining 3D] with topic of "High-quality 3D Reconstruction and Generation".Jan. 2024.
-
Give a talk at Alibaba International Digital Commerce (AIDC), "Intelligent Generation and Restoration".Dec. 2023.
-
Presentation for Huawei Central Media Research Institute, "Multi-Modality Low-Light Data Enhancement".Oct. 2023.
-
Invited talk at VALSE Webinar on "LLIE via Structure Modeling and Guidance", [News].Sep. 2023.
-
Organize a nationwide academic meeting at Hangzhou with topic of "Intelligent Computing and Security".Sep. 2023.
-
Give a talk at Zhejiang University, "Reliable Artificial Intelligence for Image Generation and Manipulation".July. 2023.
-
Presentation for CVLab at ETH, "Multi-Modality Restoration".July. 2023.
-
Invited to give a talk at HKUST, "Effective Generative Models for Real-World Manipulation and Restoration".July. 2023.
-
Invitation from JiQiZhiXin (机器之心): "White Paper for Security and Privacy of Large Generative Model", [News]June. 2023.
-
Give a talk to Alibaba DAMO Academy, with topic of "Real-world Generation for 2D and 3D Data".May. 2023.
-
Awarded with "Science Fund Program for Excellent Young Scientists at Zhejiang Lab (之江优秀青年科学基金)".Mar. 2023.
-
AI TIME Personal Talk: "Deep Parametric 3D Filters for Multiple Degradations Restoration".Mar. 2023.
-
AI TIME ECCV 2022: "Multi‑Task Learning via Transformer and Cross‑Task Reasoning".Dec. 2022.
Talks & Presentations in 2024
Talks & Presentations in 2023
Research Summary
Multi-modality Generation
Multi-modality Restoration
Multi-modality Understanding
Technical Report
-
*: equal contribution, #: corresponding author
-
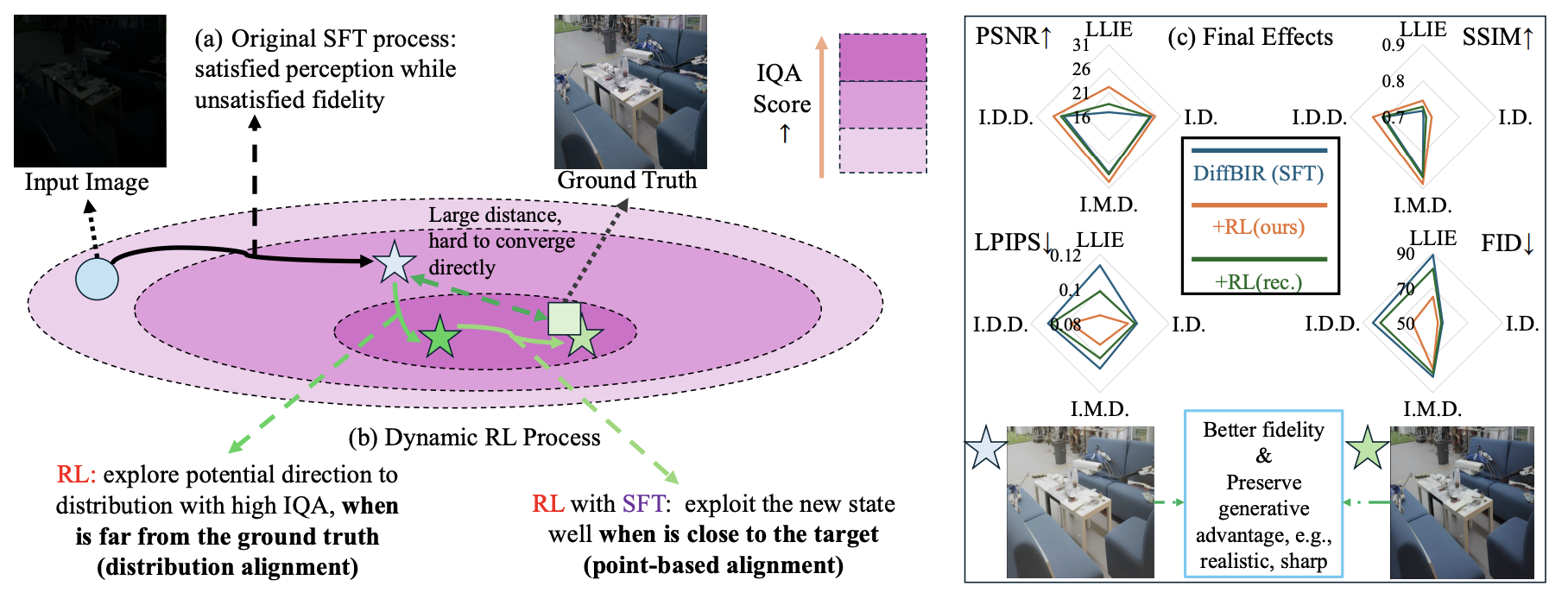 Enhancing Diffusion-based Restoration Models via Difficulty-Adaptive Reinforcement Learning with IQA Reward
Enhancing Diffusion-based Restoration Models via Difficulty-Adaptive Reinforcement Learning with IQA Reward
Xiaogang Xu, Ruihang Chu, Jian Wang, Kun Zhou, Wenjie Shu, Harry Yang, Ser-Nam Lim, Hao Chen, Liang Lin.
Arxiv, 2025. -
 Boosting Fidelity for Pre-Trained-Diffusion-Based Low-Light Image Enhancement via Condition Refinement
Boosting Fidelity for Pre-Trained-Diffusion-Based Low-Light Image Enhancement via Condition Refinement
Xiaogang Xu, Jian Wang, Yunfan Lu, Ruihang Chu, Ruixing Wang, Jiafei Wu, Bei Yu, Liang Lin.
Arxiv, 2025. -
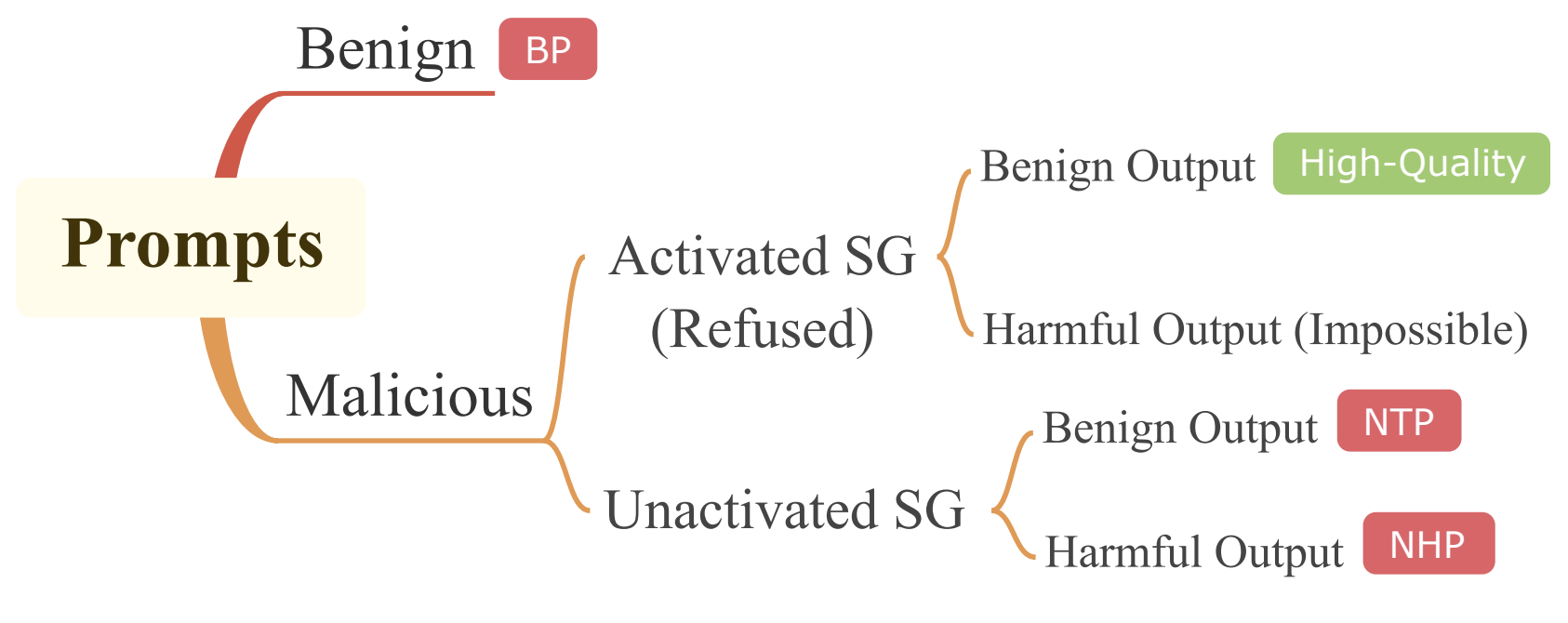 Jailbreaking Commercial Black-Box LLMs with Explicitly Harmful Prompts
Jailbreaking Commercial Black-Box LLMs with Explicitly Harmful Prompts
Chiyu Zhang, Lu Zhou, Xiaogang Xu, Jiafei Wu, Liming Fang, Zhe Liu.
Arxiv, 2025. -
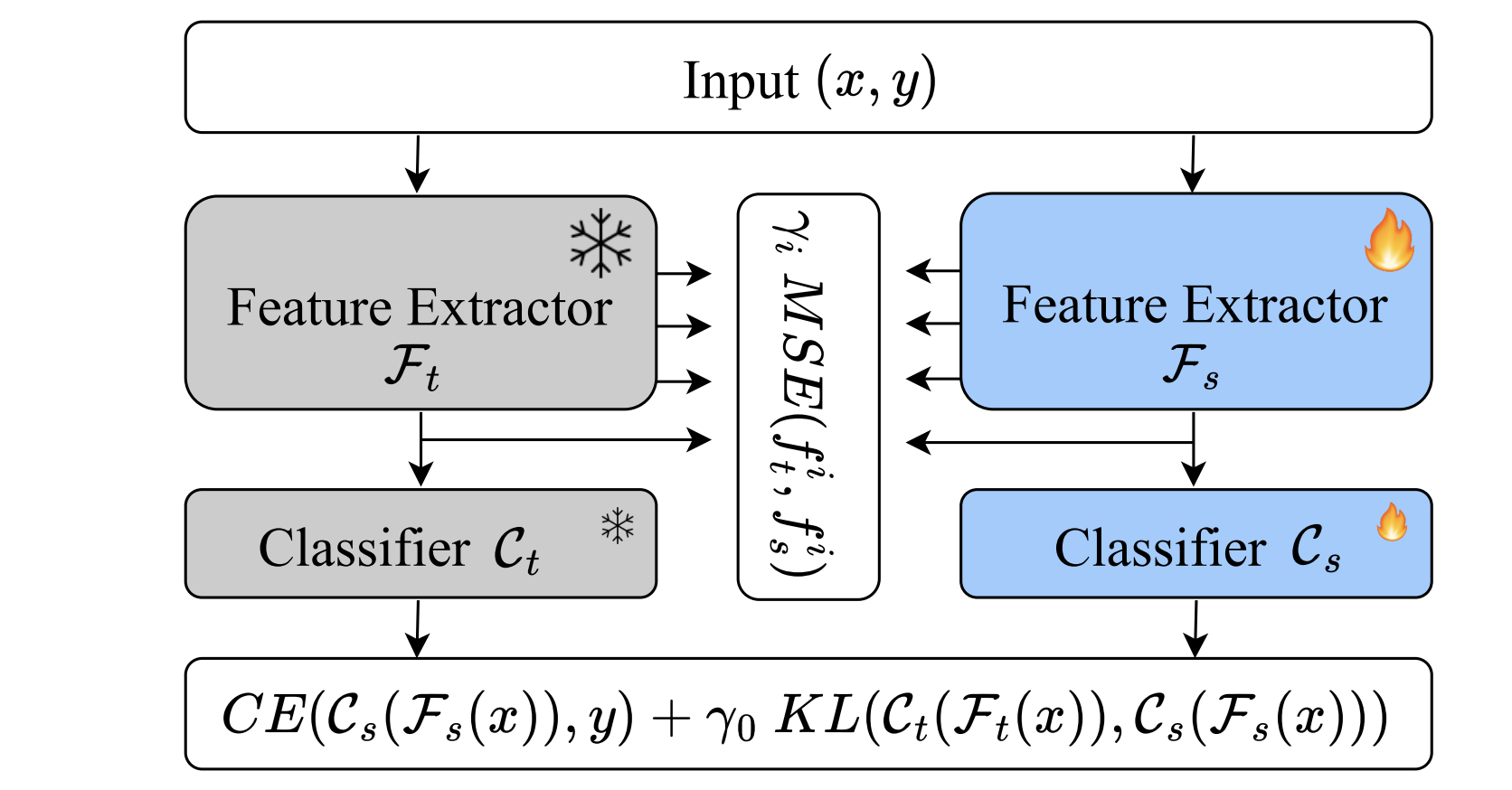 Generative Distribution Distillation
Generative Distribution Distillation
Jiequan Cui, Beier Zhu, Qingshan Xu, Xiaogang Xu, Pengguang Chen, Xiaojuan Qi, Bei Yu, Hanwang Zhang, Richang Hong.
Arxiv, 2025. -
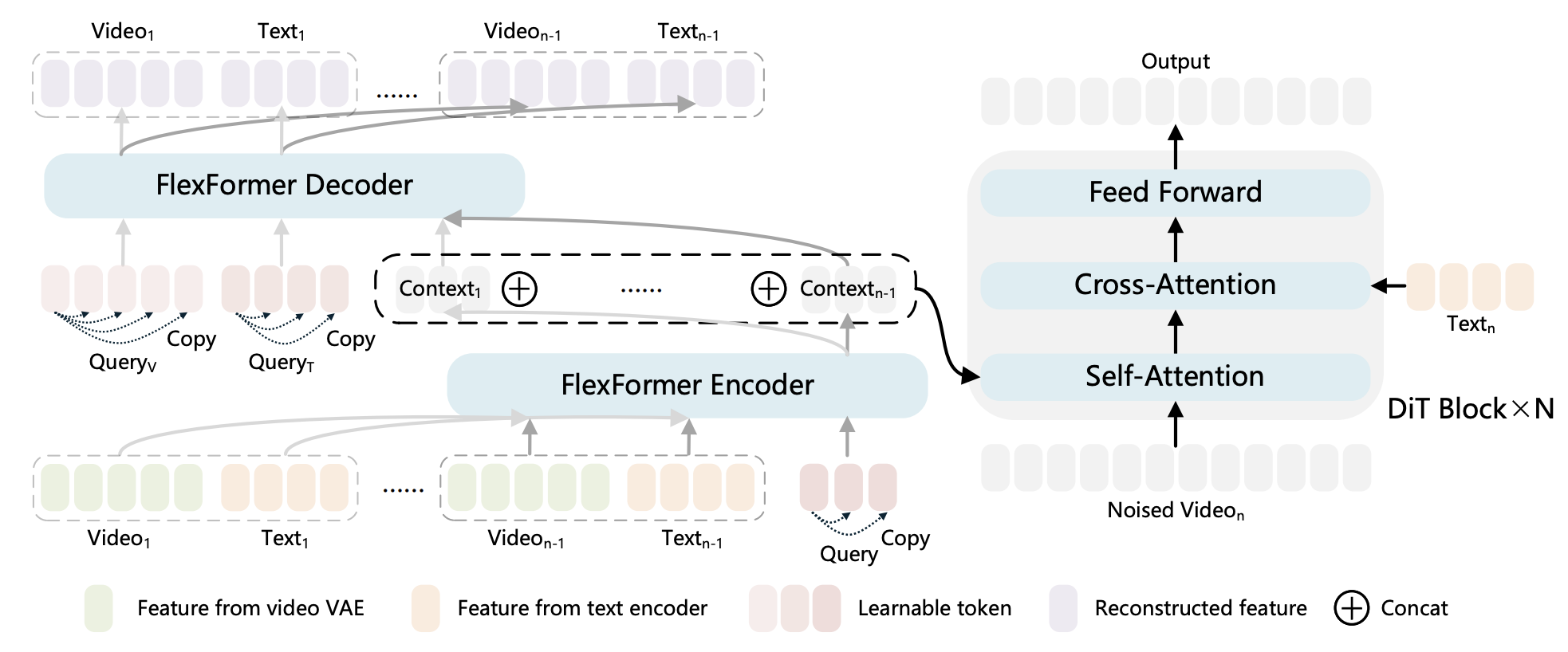 LoViC: Efficient Long Video Generation with Context Compression
LoViC: Efficient Long Video Generation with Context Compression
Jiaxiu Jiang, Wenbo Li, Jingjing Ren, Yuping Qiu, Yong Guo, Xiaogang Xu, Han Wu, Wangmeng Zuo.
Arxiv, 2025. -
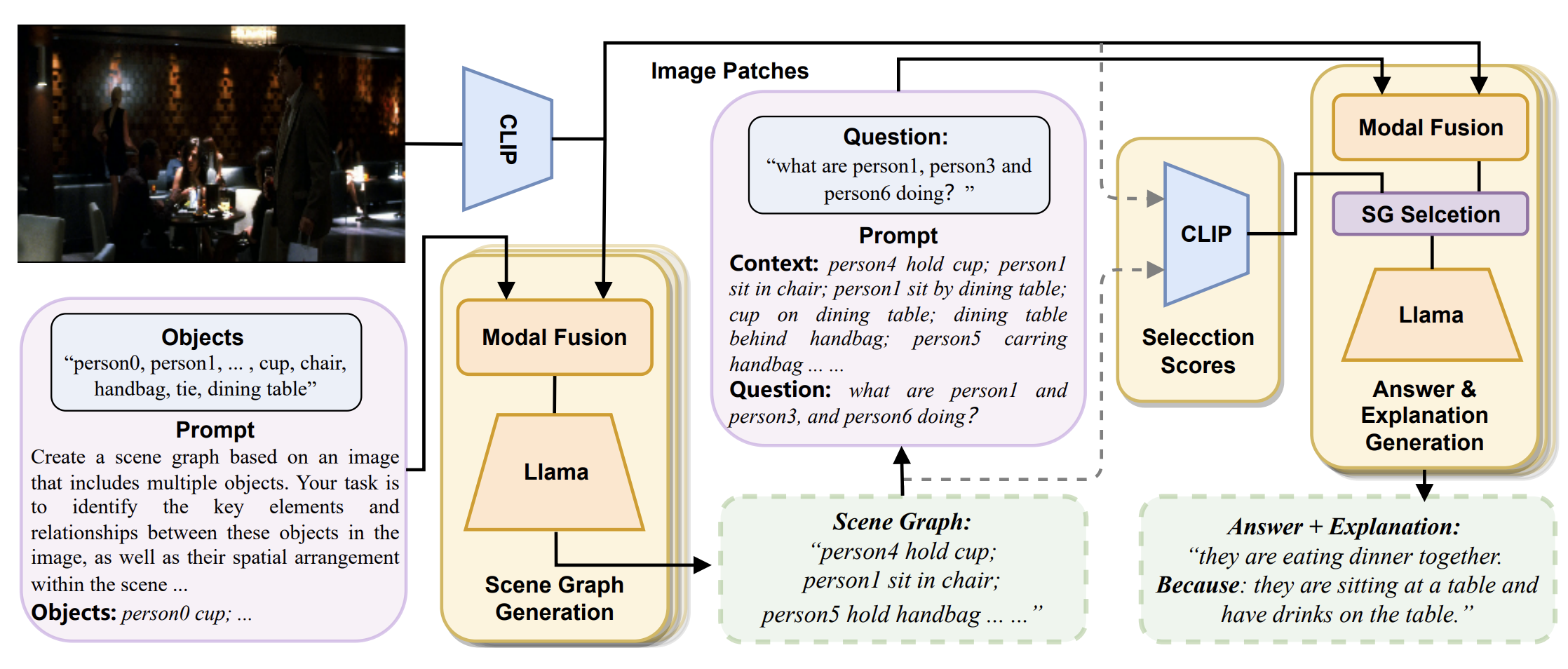 Generative Visual Commonsense Answering and Explaining with Generative Scene Graph Constructin
Generative Visual Commonsense Answering and Explaining with Generative Scene Graph Constructin
Fan Yuan, Xiaoyuan Fang, Rong Quan, Jing Li, Wei Bi, Xiaogang Xu, Piji Li.
Arxiv, 2025. -
 LPO: Towards Accurate GUI Agent Interaction via Location Preference Optimization
LPO: Towards Accurate GUI Agent Interaction via Location Preference Optimization
Jiaqi Tang, Yu Xia, Yi-Feng Wu, Yuwei Hu, Yuhui Chen, Qing-Guo Chen, Xiaogang Xu#, Xiangyu Wu, Hao Lu, Yanqing Ma, Shiyin Lu, Qifeng Chen.
Arxiv, 2025. -
 From Events to Enhancement: A Survey on Event-Based Imaging Technologies
From Events to Enhancement: A Survey on Event-Based Imaging Technologies
Yunfan Lu, Xiaogang Xu, Pengteng Li, Yusheng Wang, Yi Cui, Huizai Yao, Hui Xiong.
Arxiv, 2025. -
 Distinguish Any Fake Videos: Unleashing the Power of Large-scale Data and Motion Features
Distinguish Any Fake Videos: Unleashing the Power of Large-scale Data and Motion Features
Lichuan Ji, Yingqi Lin, Zhenhua Huang, Yan Han, Xiaogang Xu#, Jiafei Wu, Chong Wang, Zhe Liu.
Arxiv, 2024. -
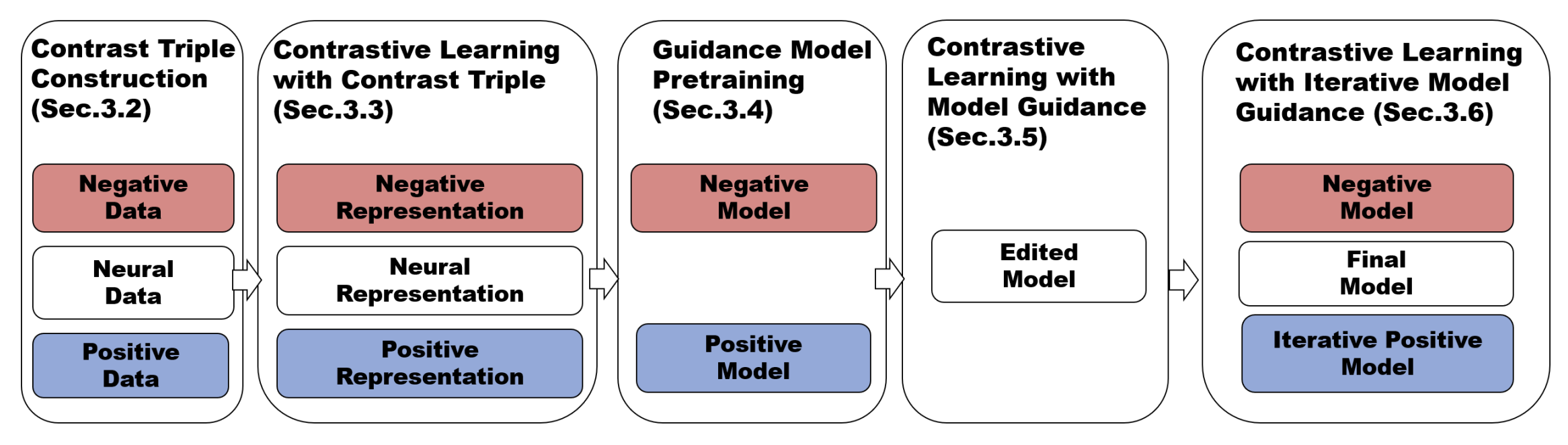 Iter-AHMCL: Alleviate Hallucination for Large Language Model via Iterative Model-level Contrastive Learning
Iter-AHMCL: Alleviate Hallucination for Large Language Model via Iterative Model-level Contrastive Learning
Huiwen Wu, Xiaohan Li, Deyi Zhang, Xiaogang Xu#, Jiafei Wu, Puning Zhao, Zhe Liu.
Arxiv, 2024. -
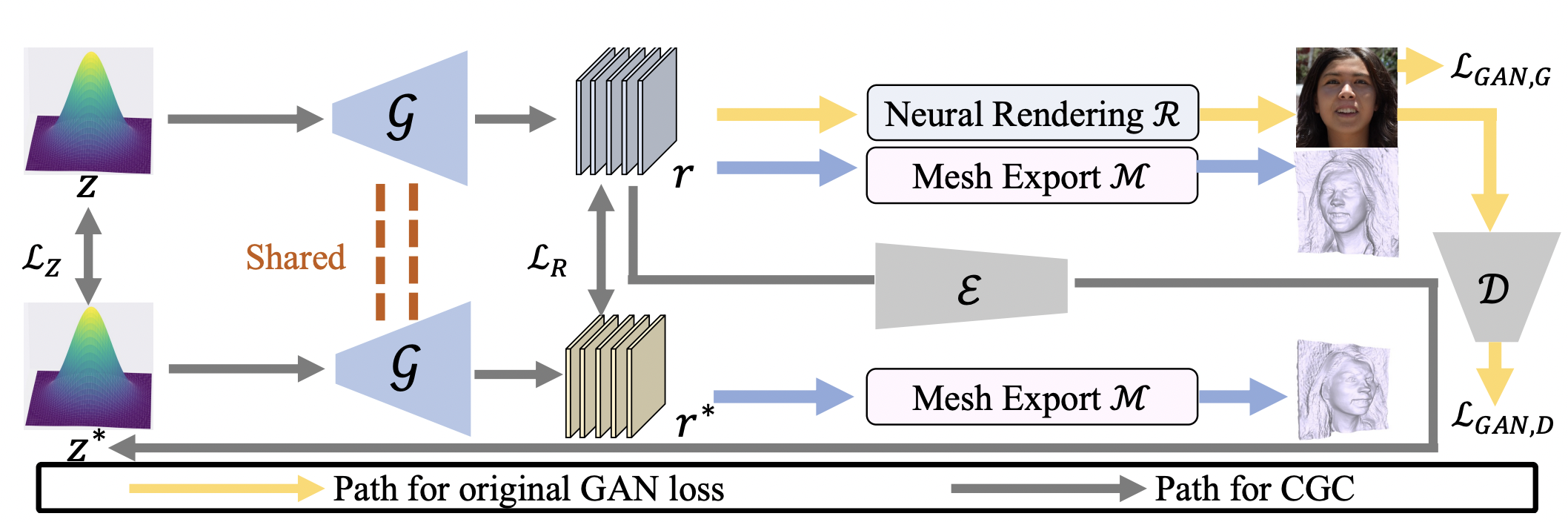 Self-supervised Learning for Enhancing Geometrical Modeling in 3D-Aware Generative Adversarial Network
Self-supervised Learning for Enhancing Geometrical Modeling in 3D-Aware Generative Adversarial Network
Jiarong Guo, Xiaogang Xu#, Hengshuang Zhao.
Arxiv, 2023. -
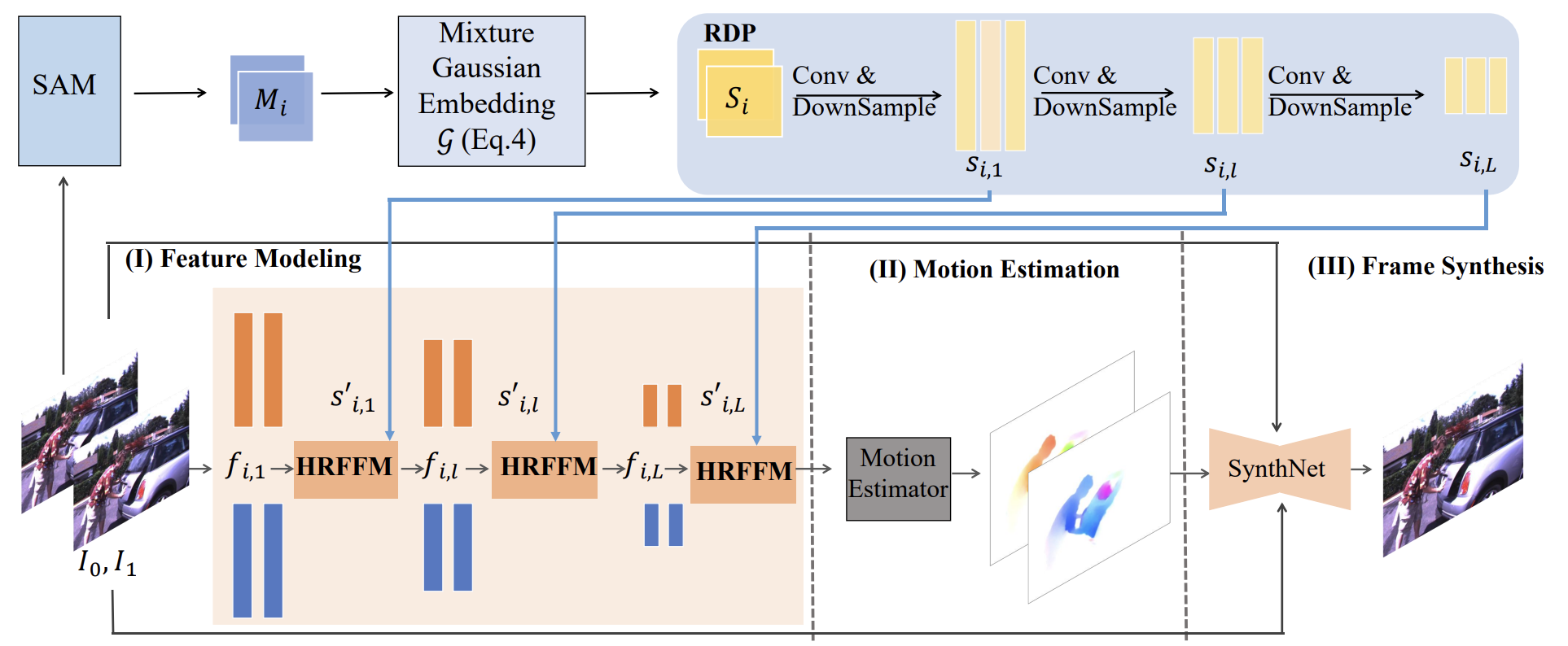 Video Frame Interpolation with Region-Distinguishable Priors from SAM
Video Frame Interpolation with Region-Distinguishable Priors from SAM
Yan Han, Xiaogang Xu#, Yingqi Lin, Jiafei Wu, Zhe Liu.
Arxiv, 2023. -
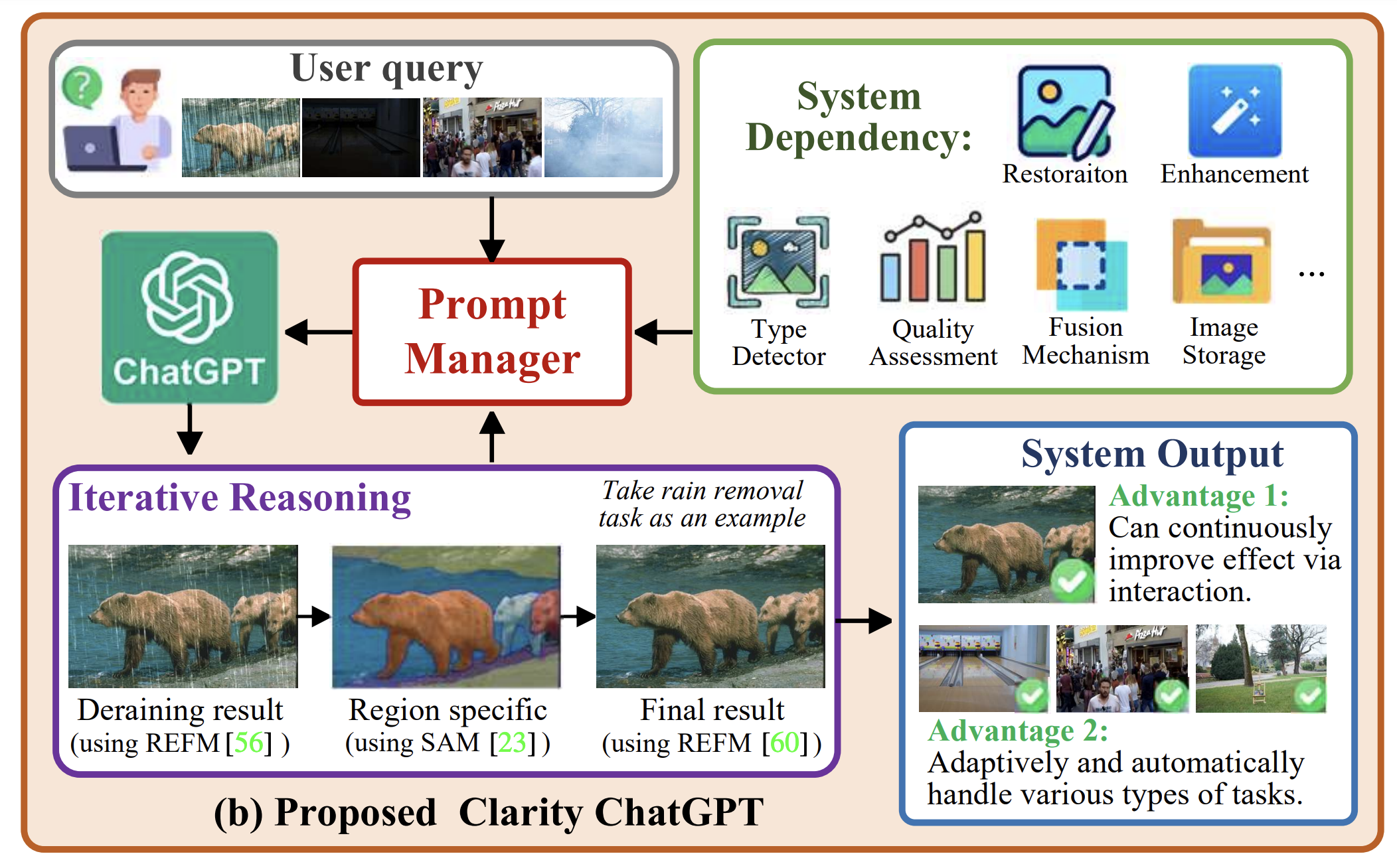 Clarity ChatGPT: An Interactive and Adaptive Processing System for Image Restoration and Enhancement
Clarity ChatGPT: An Interactive and Adaptive Processing System for Image Restoration and Enhancement
Yanyan Wei, Zhao Zhang, Jiahuan Ren, Xiaogang Xu, Richang Hong, Yi Yang, Shuicheng Yan, Meng Wang.
Arxiv, 2023. -
 General Adversarial Defense Against Black-box Attacks via Pixel Level and Feature Level Distribution Alignments
General Adversarial Defense Against Black-box Attacks via Pixel Level and Feature Level Distribution Alignments
Xiaogang Xu, Hengshuang Zhao, Philip Torr, Jiaya Jia.
Arxiv, 2022.
Full Reports in 2025
Full Reports in 2024
Full Reports in 2023
Full Reports in 2022
Publications [Google Scholar]
-
*: equal contribution, #: corresponding author
-
 Learnable Feature Patches and Vectors for Boosting Low-light Image Enhancement without External Knowledge
Learnable Feature Patches and Vectors for Boosting Low-light Image Enhancement without External Knowledge
Xiaogang Xu, Jiafei Wu, Qingsen Yan, Jiequan Cui, Richang Hong, Bei Yu.
ICCV, 2025. -
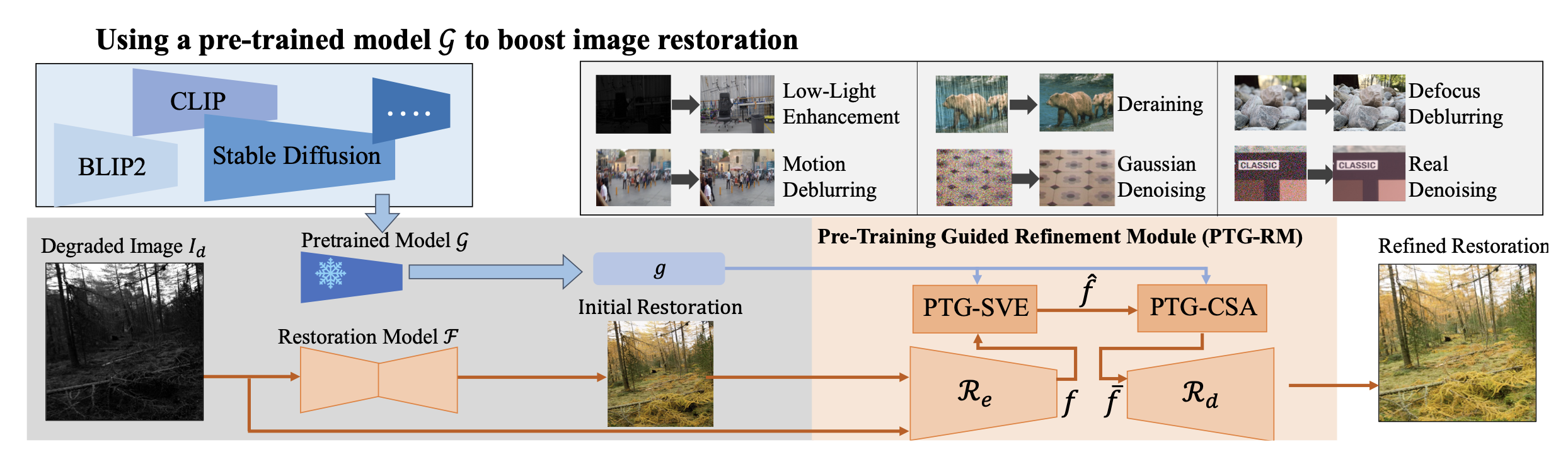 Boosting Image Restoration via Priors from Pre-trained Models
Boosting Image Restoration via Priors from Pre-trained Models
Xiaogang Xu, Shu Kong, Tao Hu, Zhe Liu, Hujun Bao.
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024, (acceptance rate 23.6% (2719/11532)). -
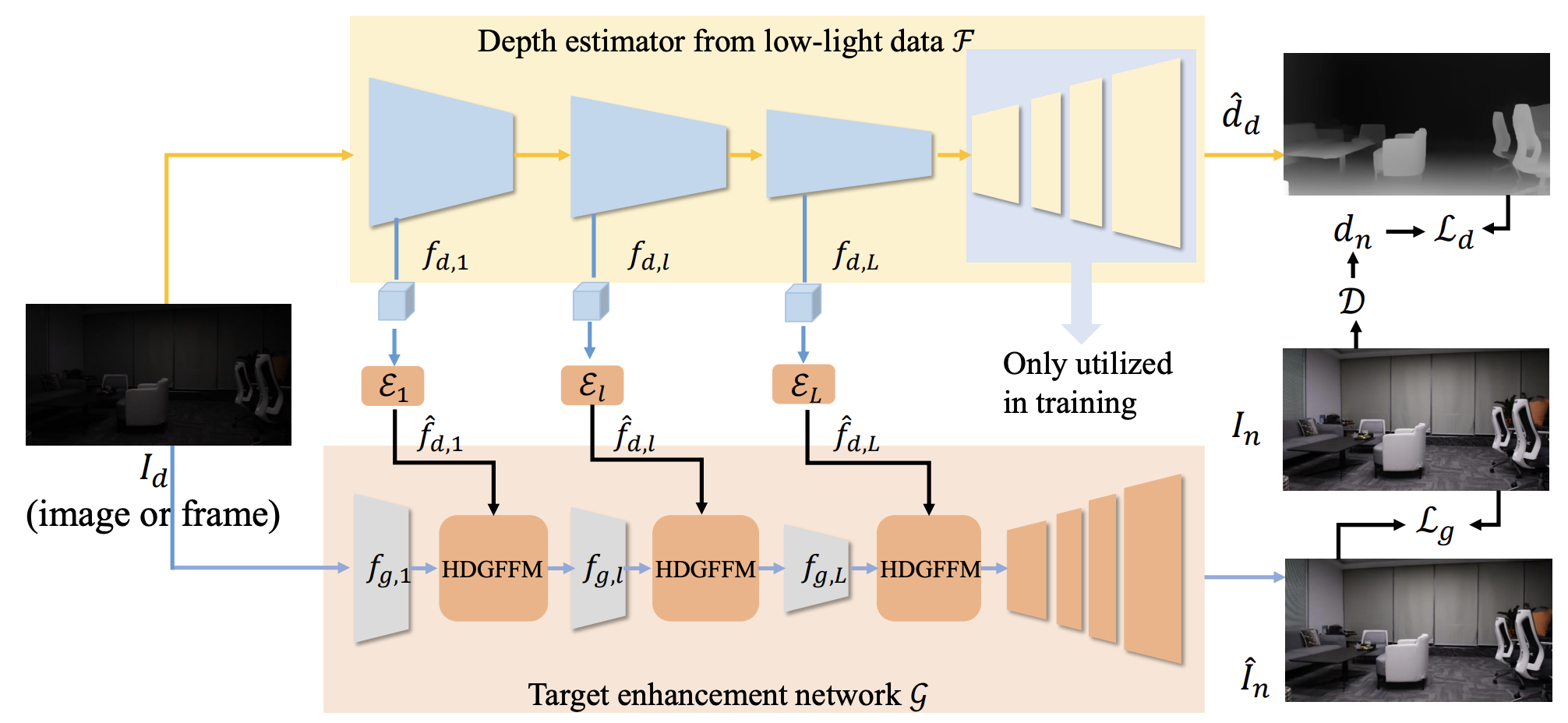 Geometric-Aware Low-Light Image and Video Enhancement via Depth Guidance
Geometric-Aware Low-Light Image and Video Enhancement via Depth Guidance
Yingqi Lin*, Xiaogang Xu*#, Jiafei Wu, Yan Han, Zhe Liu.
IEEE Transactions on Image Processing (TIP), 2025. -
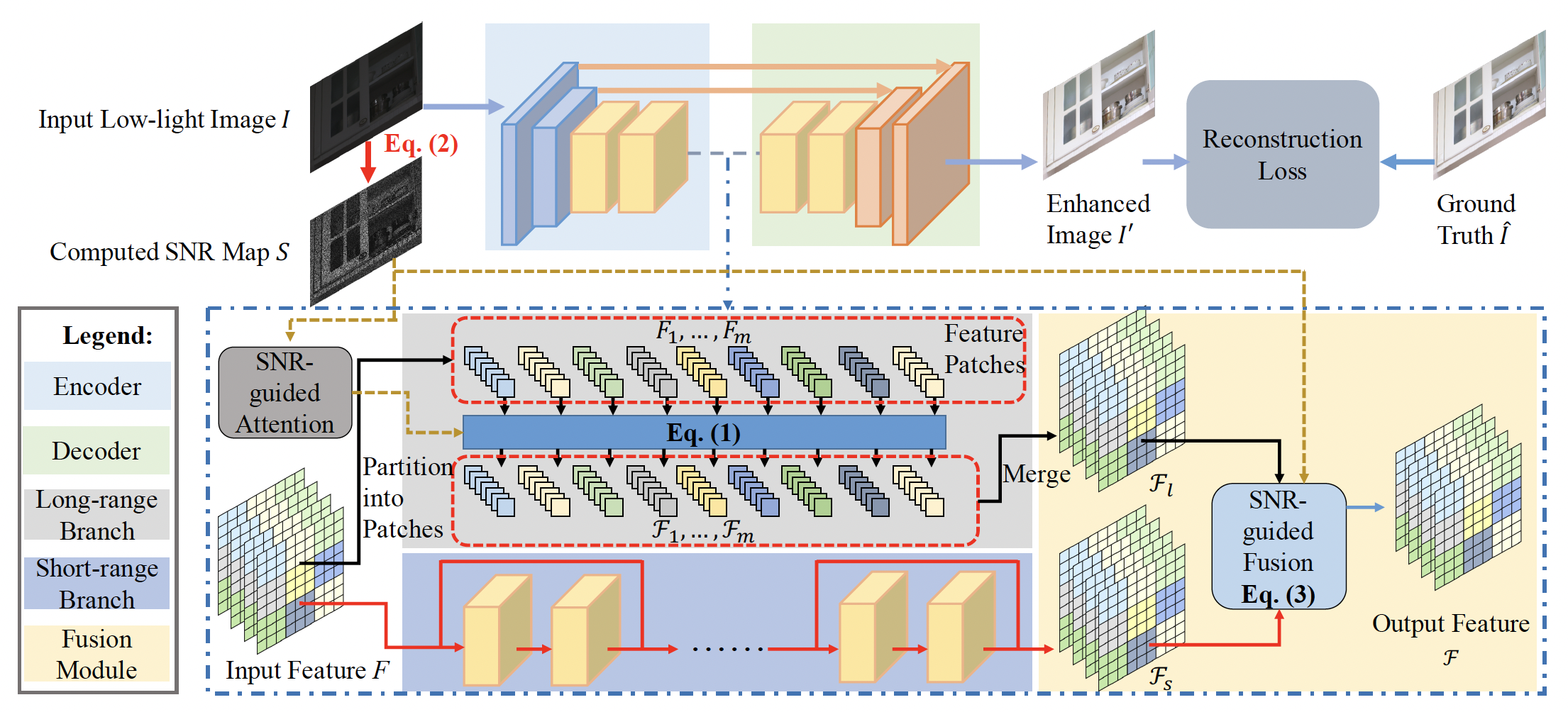 SNR-Aware Low-light Image Enhancement
SNR-Aware Low-light Image Enhancement
Xiaogang Xu, Ruixing Wang, Chi-Wing Fu, Jiaya Jia.
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2022 (acceptance rate 25.3% (2067/8161)). -
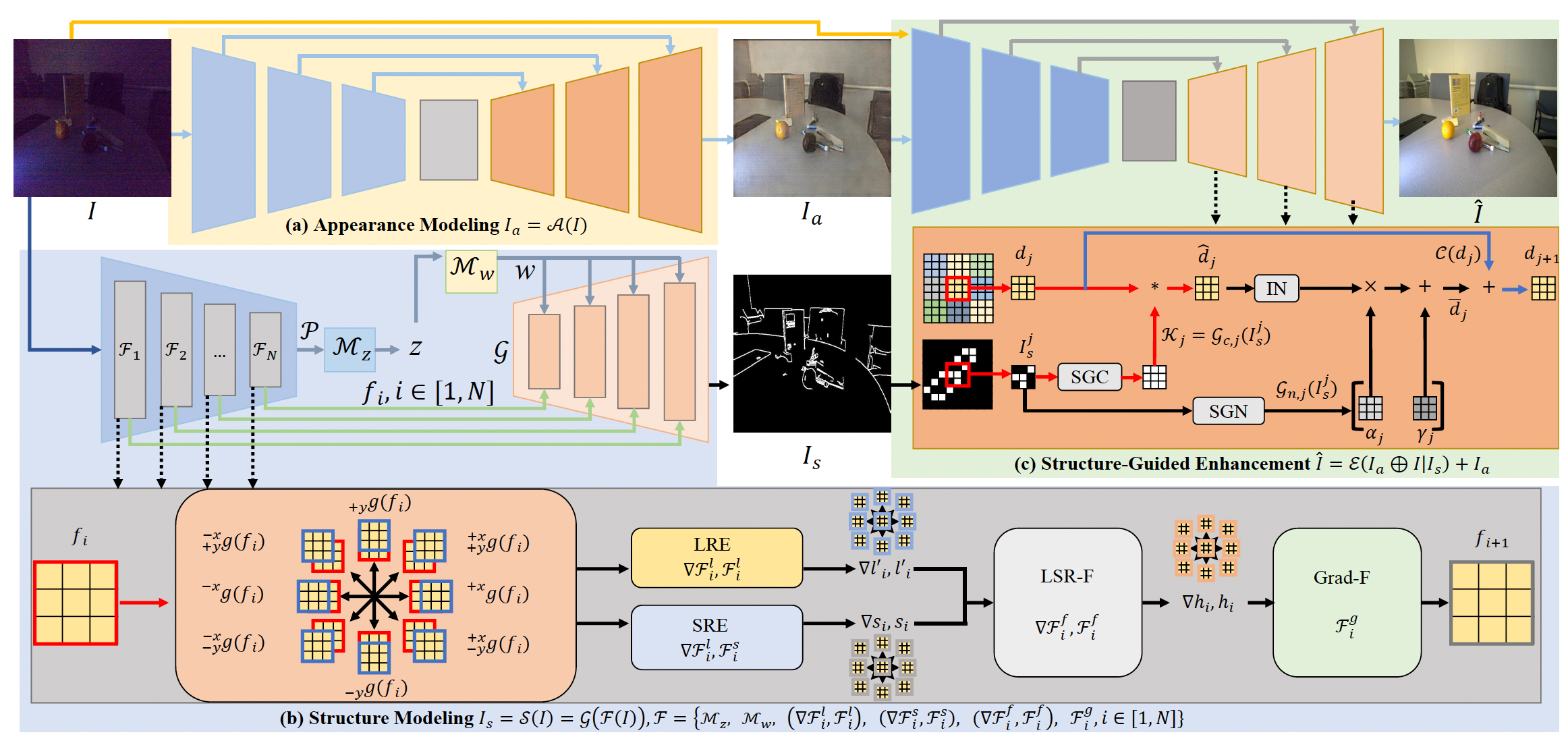 Low‑light Image Enhancement via Structure Modeling and Guidance
Low‑light Image Enhancement via Structure Modeling and Guidance
Xiaogang Xu, Ruixing Wang, Jiangbo Lv.
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2023 (acceptance rate 25.8% (2340/9155)). -
 Low-Light Video Enhancement via Spatial-Temporal Consistent Decomposition
Low-Light Video Enhancement via Spatial-Temporal Consistent Decomposition
Xiaogang Xu, Kun Zhou, Tao Hu, Jiafei Wu, Ruixing Wang, Hao Peng, Bei Yu.
IJCAI, 2025. -
 Deep Parametric 3D Filters for Joint Video Denoising and Illumination Enhancement in Video Super Resolution
Deep Parametric 3D Filters for Joint Video Denoising and Illumination Enhancement in Video Super Resolution
Xiaogang Xu, Ruixing Wang, Chi-Wing Fu, Jiaya Jia.
AAAI Conference on Artificial Intelligence (AAAI), 2023 Oral (acceptance rate 19.6% (1721/8777)). -
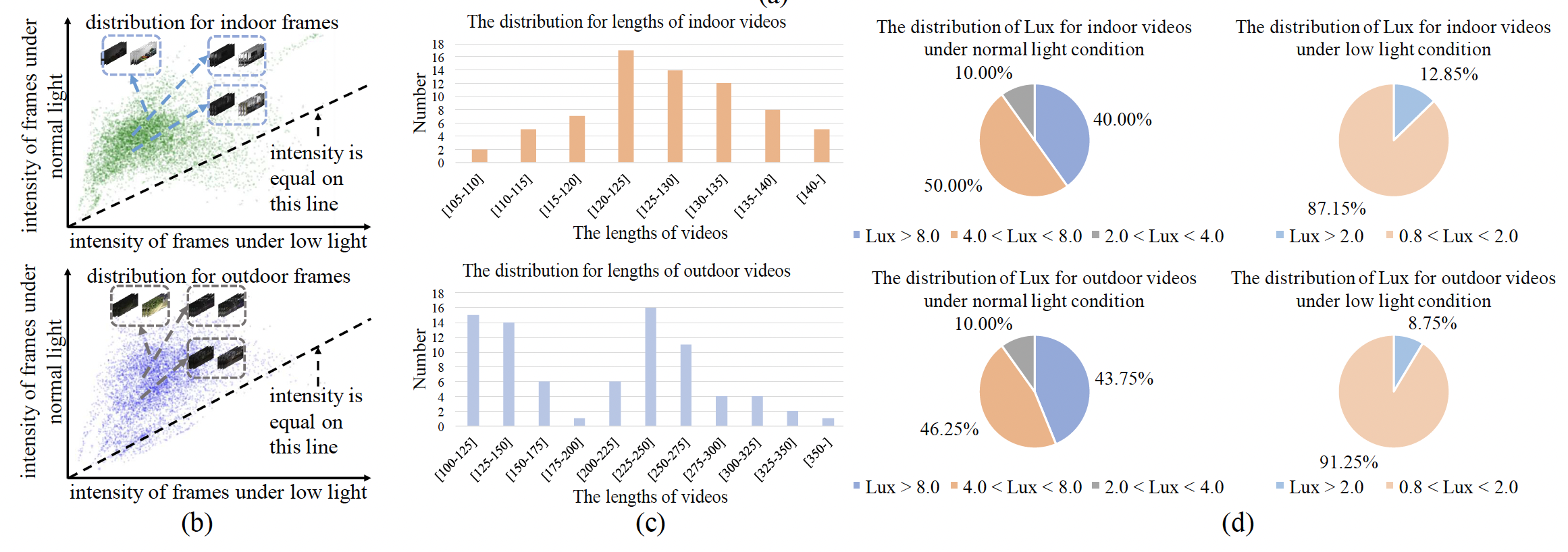 Seeing Dynamic Scene in the Dark: A High-Quality Video Dataset with Mechatronic Alignment
Seeing Dynamic Scene in the Dark: A High-Quality Video Dataset with Mechatronic Alignment
Ruixing Wang*, Xiaogang Xu*, Chi-Wing Fu, Jiangbo Lu, Bei Yu, Jiaya Jia.
IEEE International Conference on Computer Vision (ICCV), 2021 (acceptance rate 26.2% (1612/6152)). -
 Wan-Move: Motion-controllable Video Generation via Latent Trajectory Guidance
Wan-Move: Motion-controllable Video Generation via Latent Trajectory Guidance
Ruihang Chu, Yefei He, Zhekai Chen, Shiwei Zhang, Xiaogang Xu, Bin Xia, Dingdong WANG, Hongwei Yi, Xihui Liu, Hengshuang Zhao, Yu Liu, Yingya Zhang, Yujiu Yang.
NeurIPS, 2025. -
 DiffDoctor: Diagnosing Image Diffusion Models Before Treating
DiffDoctor: Diagnosing Image Diffusion Models Before Treating
Yiyang Wang, Xi Chen, Xiaogang Xu#, Sihui Ji, Yu Liu, Yujun Shen, Hengshuang Zhao.
ICCV, 2025. -
 FashionComposer: Compositional Fashion Image Generations
FashionComposer: Compositional Fashion Image Generations
Sihui Ji, Yiyang Wang, Xi Chen, Xiaogang Xu, Hao Luo, Hengshuang Zhao.
SIGGRAPH, 2025. -
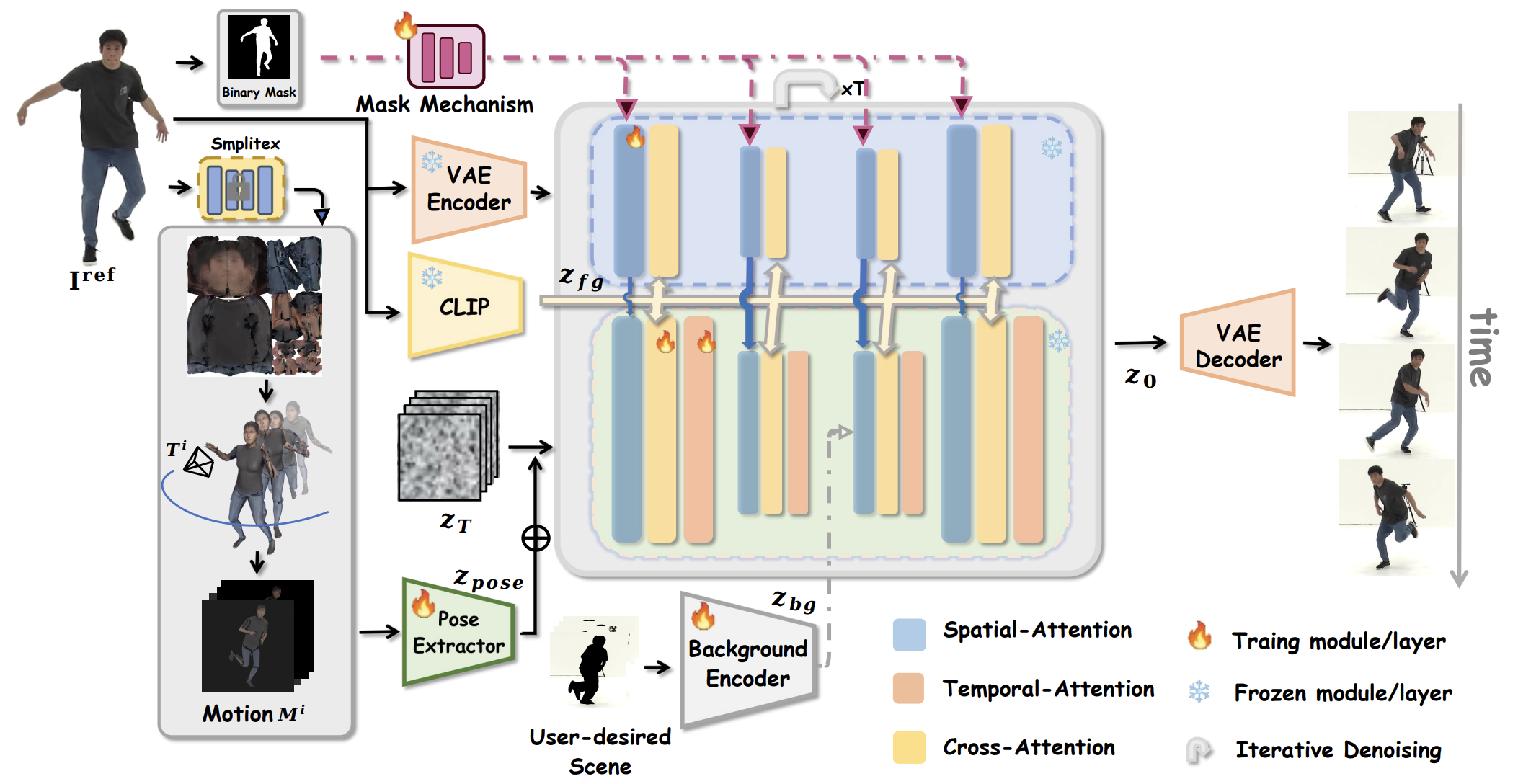 CFSynthesis: Controllable and free-view 3d human video synthesis
CFSynthesis: Controllable and free-view 3d human video synthesis
Liyuan Cui, Xiaogang Xu#, Wenqi Dong, Zesong Yang, Hujun Bao, Zhaopeng Cui.
ICMR, 2025. -
 LucidDreamer: Towards High-Fidelity Text-to-3D Generation via Interval Score Matching
LucidDreamer: Towards High-Fidelity Text-to-3D Generation via Interval Score Matching
Yixun Liang, Xin Yang, Jiantao Lin, Haodong Li, Xiaogang Xu, Yingcong Chen.
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024, (Highlight, acceptance rate 2.8% (324/11532)). -
 S2WAT: Image Style Transfer via Hierarchical Vision Transformer using Strips Window Attention
S2WAT: Image Style Transfer via Hierarchical Vision Transformer using Strips Window Attention
Chiyu Zhang, Xiaogang Xu#, Lei Wang, Zaiyan Dai, Jun Yang.
AAAI Conference on Artificial Intelligence (AAAI), 2024, (acceptance rate 26.1% (2342/9862)). -
 Photo-Realistic Out-of-domain GAN inversion via Invertibility Decomposition
Photo-Realistic Out-of-domain GAN inversion via Invertibility Decomposition
Xin Yang, Xiaogang Xu#, Yingcong Chen#.
IEEE International Conference on Computer Vision (ICCV), 2023, (acceptance rate 26.8% (2162/8068)). -
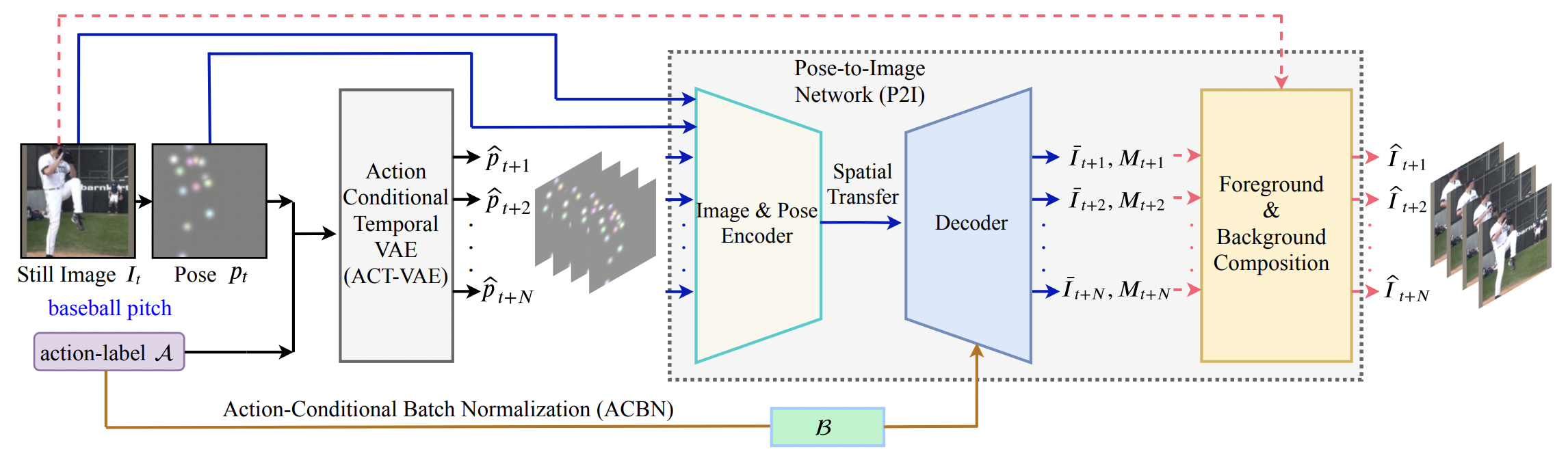 Conditional Temporal Variational AutoEncoder for Action Video Prediction
Conditional Temporal Variational AutoEncoder for Action Video Prediction
Xiaogang Xu, Yi Wang, Liwei Wang, Bei Yu, Jiaya Jia.
International Journal of Computer Vision (IJCV), 2023. -
 Hierarchical Image Generation via Transformer-Based Sequential Patch Selection
Hierarchical Image Generation via Transformer-Based Sequential Patch Selection
Xiaogang Xu, Ning Xu.
AAAI Conference on Artificial Intelligence (AAAI), 2022 (acceptance rate 15.0% (1349/9020)). -
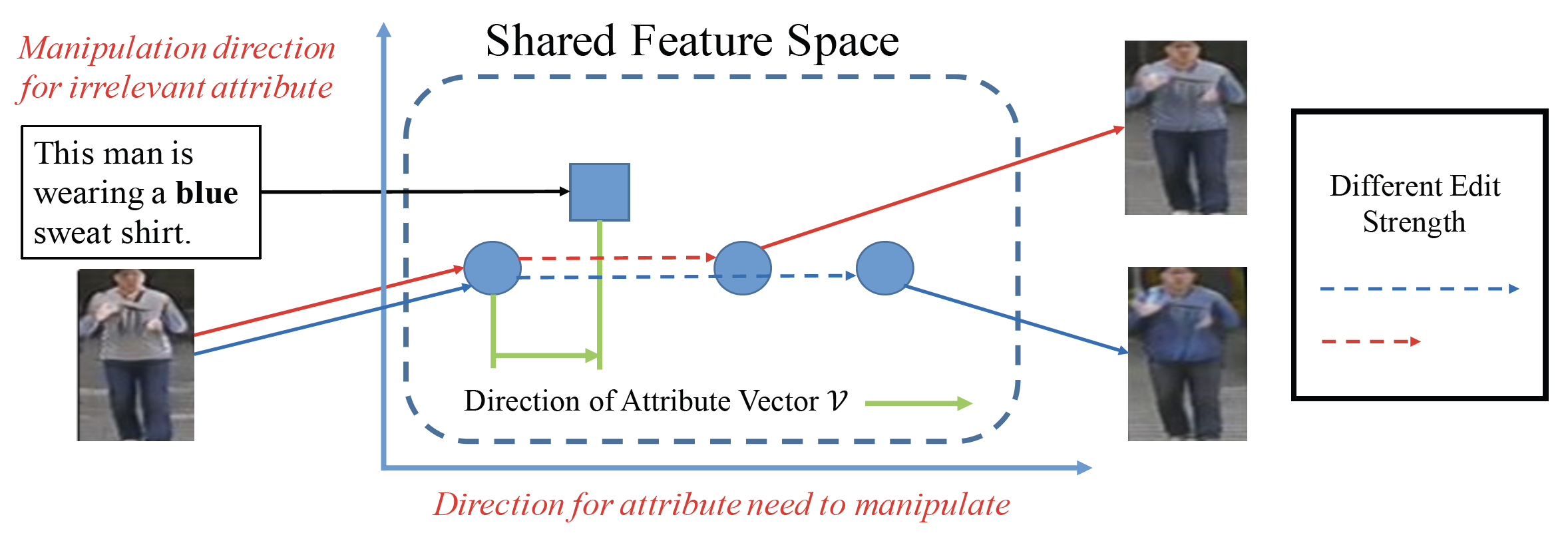 Text-Guided Human Image Manipulation via Image-Text Shared Space
Text-Guided Human Image Manipulation via Image-Text Shared Space
Xiaogang Xu, Yingcong Chen, Jiaya Jia.
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2021. -
 View Independent Generative Adversarial Network for Novel View Synthesis
View Independent Generative Adversarial Network for Novel View Synthesis
Xiaogang Xu, Yingcong Chen, Jiaya Jia.
IEEE International Conference on Computer Vision (ICCV), 2019 Oral (acceptance rate 4.3% (187/4304)).[Paper] Code
-
 Depth Anything V2
Depth Anything V2
Lihe Yang, Bingyi Kang, Zilong Huang, Zhen Zhao, Xiaogang Xu, Jiashi Feng, Hengshuang Zhao.
Conference on Neural Information Processing Systems (NeurIPS), 2024, (acceptance rate 25.8%). -
 Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data
Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data
Lihe Yang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, Hengshuang Zhao.
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024, (acceptance rate 23.6% (2719/11532), also accepted by CVPR 2024 Demo Track). -
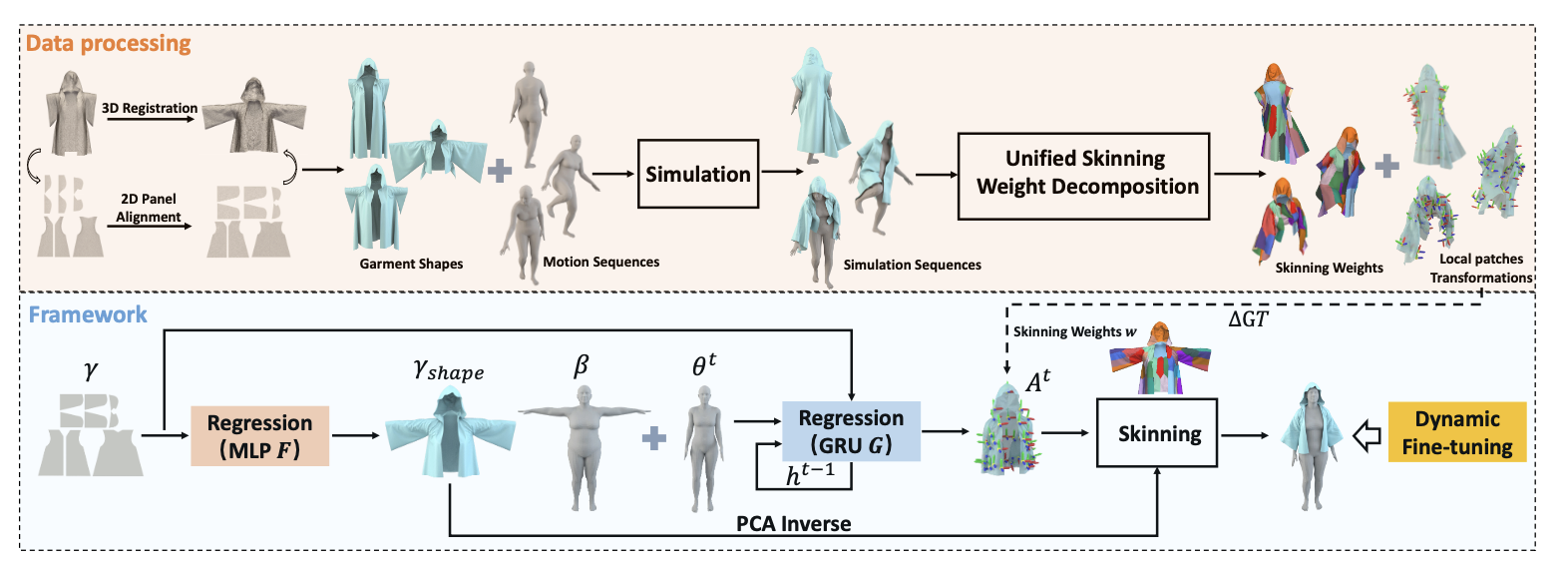 Parametric Linear Blend Skinning Model for Multiple-Shape 3D Garments
Parametric Linear Blend Skinning Model for Multiple-Shape 3D Garments
Xipeng Chen, Guangrun Wang, Xiaogang Xu, Philip Torr, Liang Lin.
IEEE Transactions on Visualization and Computer Graphics (TVCG), 2024. -
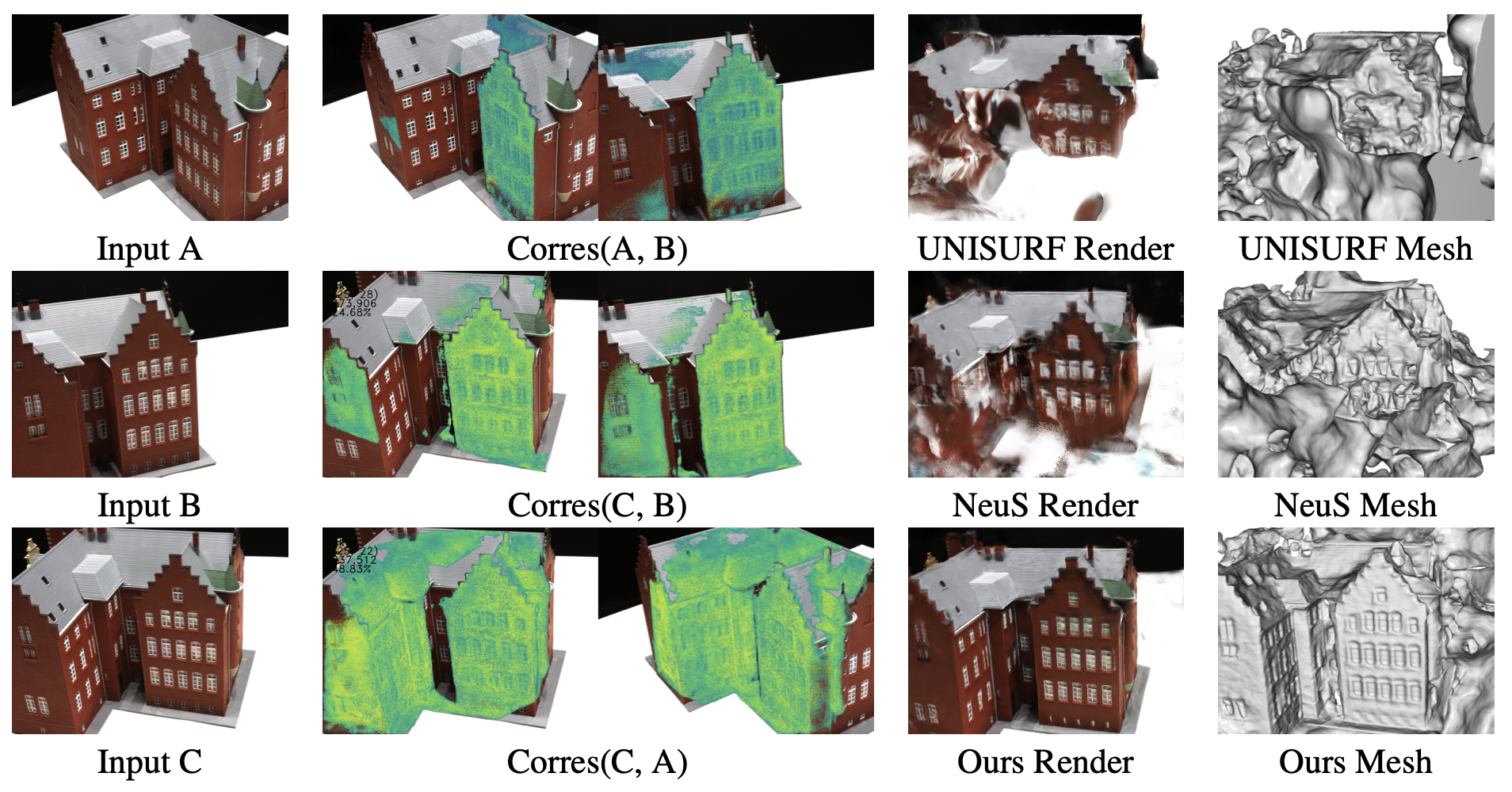 CorresNeRF: Image Correspondence Priors for Neural Radiance Fields
CorresNeRF: Image Correspondence Priors for Neural Radiance Fields
Yixing Lao, Xiaogang Xu, Xihui Liu, Hengshuang Zhao.
Conference on Neural Information Processing Systems (NeurIPS), 2023, (acceptance rate 26.1% (3221/12343)). -
 Lighting up NeRF via Unsupervised Decomposition and Enhancement
Lighting up NeRF via Unsupervised Decomposition and Enhancement
Haoyuan Wang, Xiaogang Xu, Ke Xu, Rynson Lau.
IEEE International Conference on Computer Vision (ICCV), 2023, (acceptance rate 26.8% (2162/8068)). -
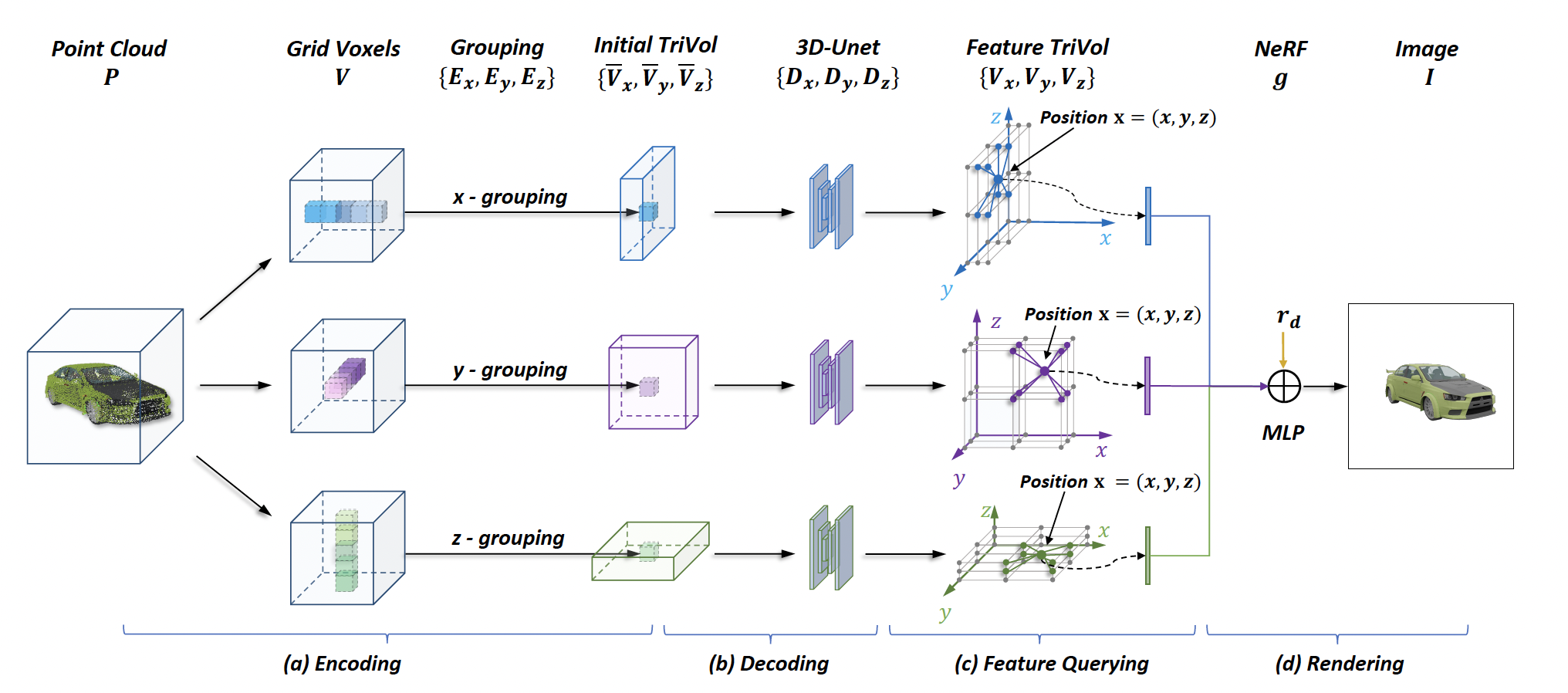 TriVol: Point Cloud Rendering Via Triple Volumes
TriVol: Point Cloud Rendering Via Triple Volumes
Tao Hu*, Xiaogang Xu*, Ruihang Chu, Jiaya Jia.
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2023 (acceptance rate 25.8% (2340/9155)). -
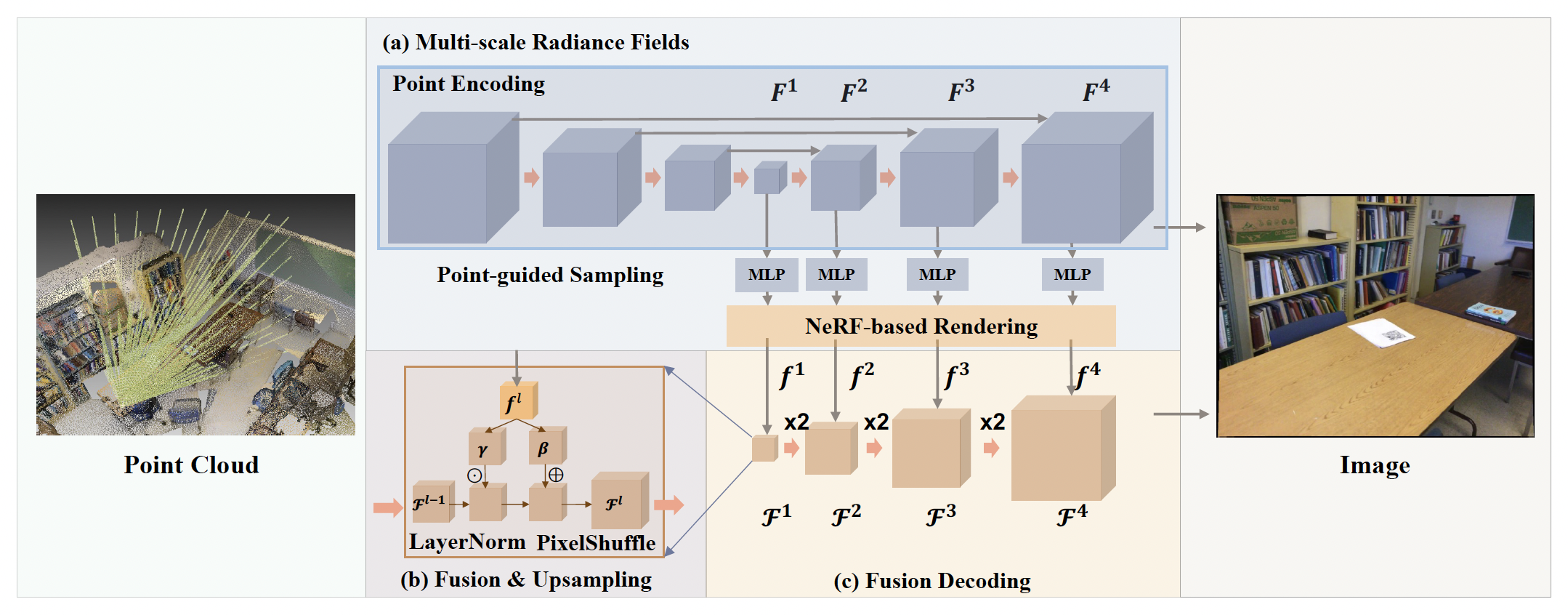 Point2Pix: Photo‑Realistic Point Cloud Rendering via Neural Radiance Fields
Point2Pix: Photo‑Realistic Point Cloud Rendering via Neural Radiance Fields
Tao Hu, Xiaogang Xu#, Shu Liu, Jiaya Jia.
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2023 (acceptance rate 25.8% (2340/9155)). -
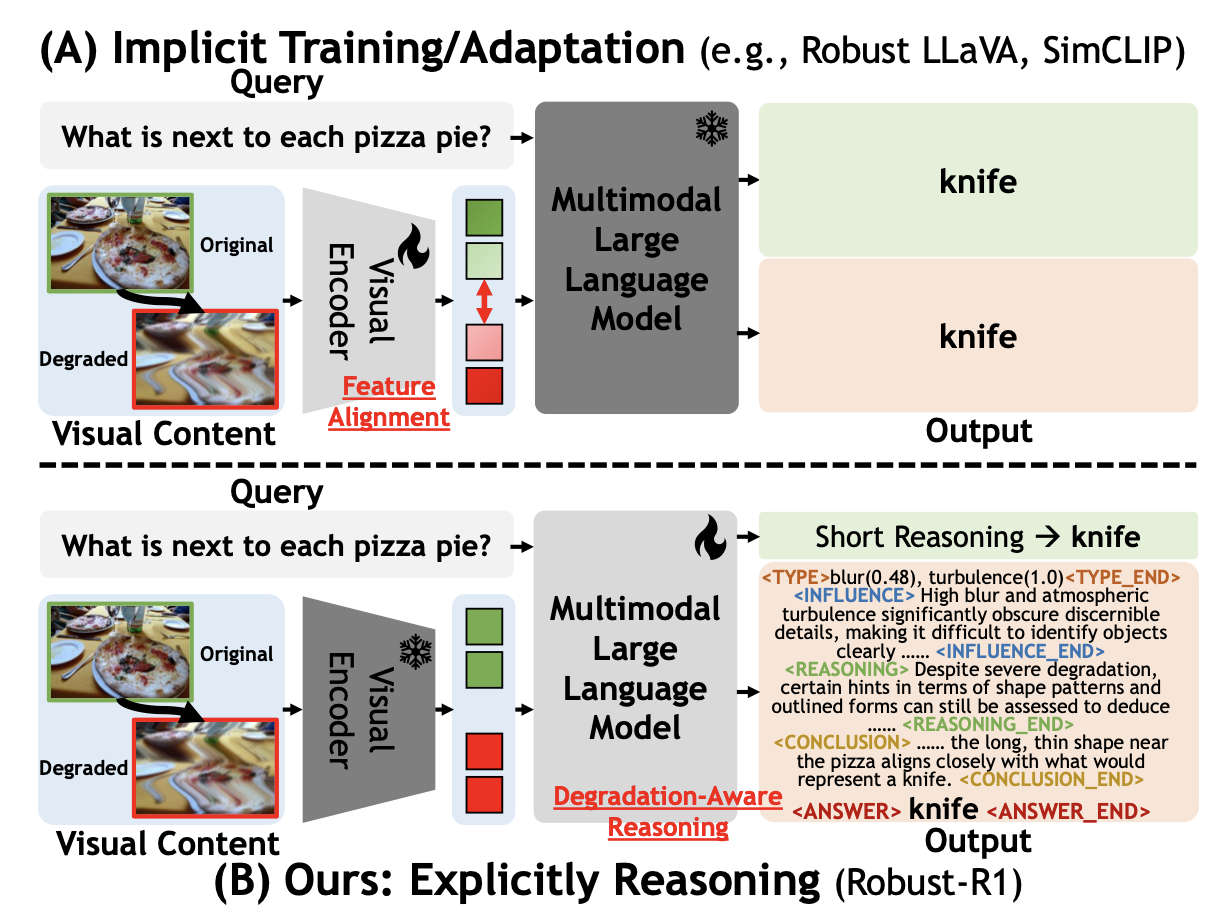 Robust-R1: Degradation-Aware Reasoning for Robust Visual Understanding
Robust-R1: Degradation-Aware Reasoning for Robust Visual Understanding
Jiaqi Tang, Jianmin Chen, Wei Wei, Xiaogang Xu, Runtao Liu, Xiangyu Wu, Qipeng Xie, Jiafei Wu Wu, Lei Zhang, Qifeng Chen.
AAAI, 2026. -
 MiCo: Multi-image Contrast for Reinforcement Visual Reasoning
MiCo: Multi-image Contrast for Reinforcement Visual Reasoning
Xi Chen, Mingkang Zhu, Shaoteng Liu, Xiaoyang Wu, Xiaogang Xu, Yu Liu, Xiang Bai, Hengshuang Zhao.
NeurIPS, 2025. -
 LARM: Large Auto-Regressive Model for Long-Horizon Embodied Intelligence
LARM: Large Auto-Regressive Model for Long-Horizon Embodied Intelligence
Zhuoling Li, Xiaogang Xu, Zhenhua Xu, SerNam Lim, Hengshuang Zhao.
ICML, 2025. -
 Hawk: Learning to Understand Open-World Video Anomalies
Hawk: Learning to Understand Open-World Video Anomalies
Jiaqi Tang, Hao Lu, Ruizheng Wu, Xiaogang Xu, Ke Ma, Cheng Fang, Bin Guo, Jiangbo Lu, Qifeng Chen, Ying-Cong Chen.
Conference on Neural Information Processing Systems (NeurIPS), 2024, (acceptance rate 25.8%). -
 Towards Efficient Large-Scale Language-3D Representation Learning
Towards Efficient Large-Scale Language-3D Representation Learning
Shentong Mo, Xiaogang Xu, Tongzhou Wang, Antonio Torralba, Shuang Li.
International Conference on Machine Learning (ICML), 2024, (acceptance rate 27.5% (2609/9473)). -
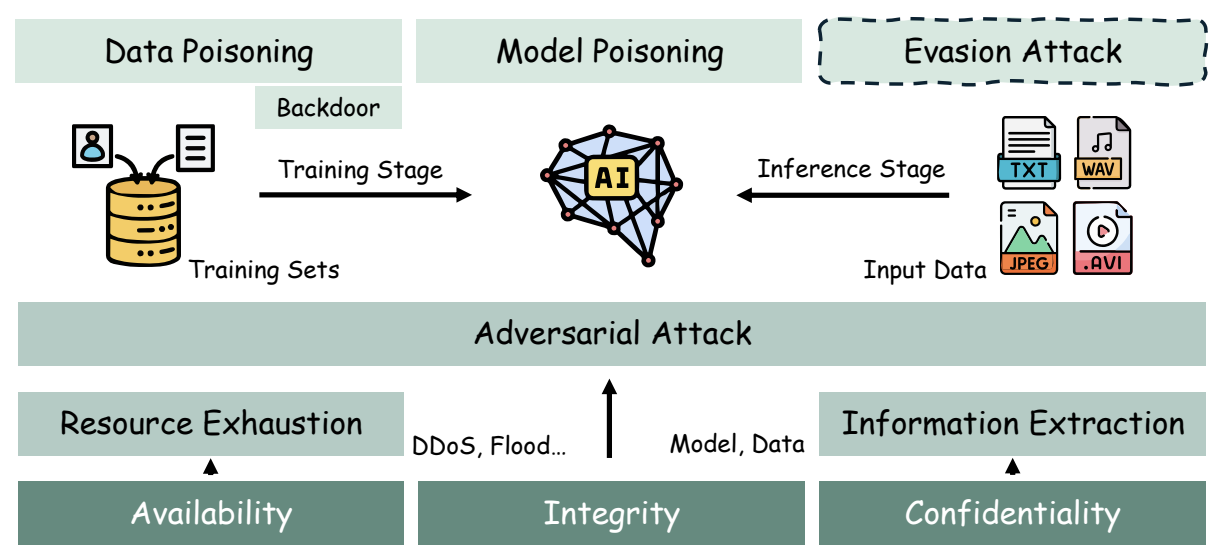 Adversarial Attacks of Vision Tasks in the Past 10 Years: A Survey
Adversarial Attacks of Vision Tasks in the Past 10 Years: A Survey
Chiyu Zhang, Xiaogang Xu#, Jiafei Wu, Zhe Liu, Lu Zhou.
ACM Computing Surveys, 2025. -
 DR-Encoder: Encode Low-rank Gradients with Random Prior for Large Language Models Differentially Privately
DR-Encoder: Encode Low-rank Gradients with Random Prior for Large Language Models Differentially Privately
Huiwen Wu, Deyi Zhang, Xiaohan Li, Xiaogang Xu#, Jiafei Wu, Zhe Liu.
AAAI, 2025. -
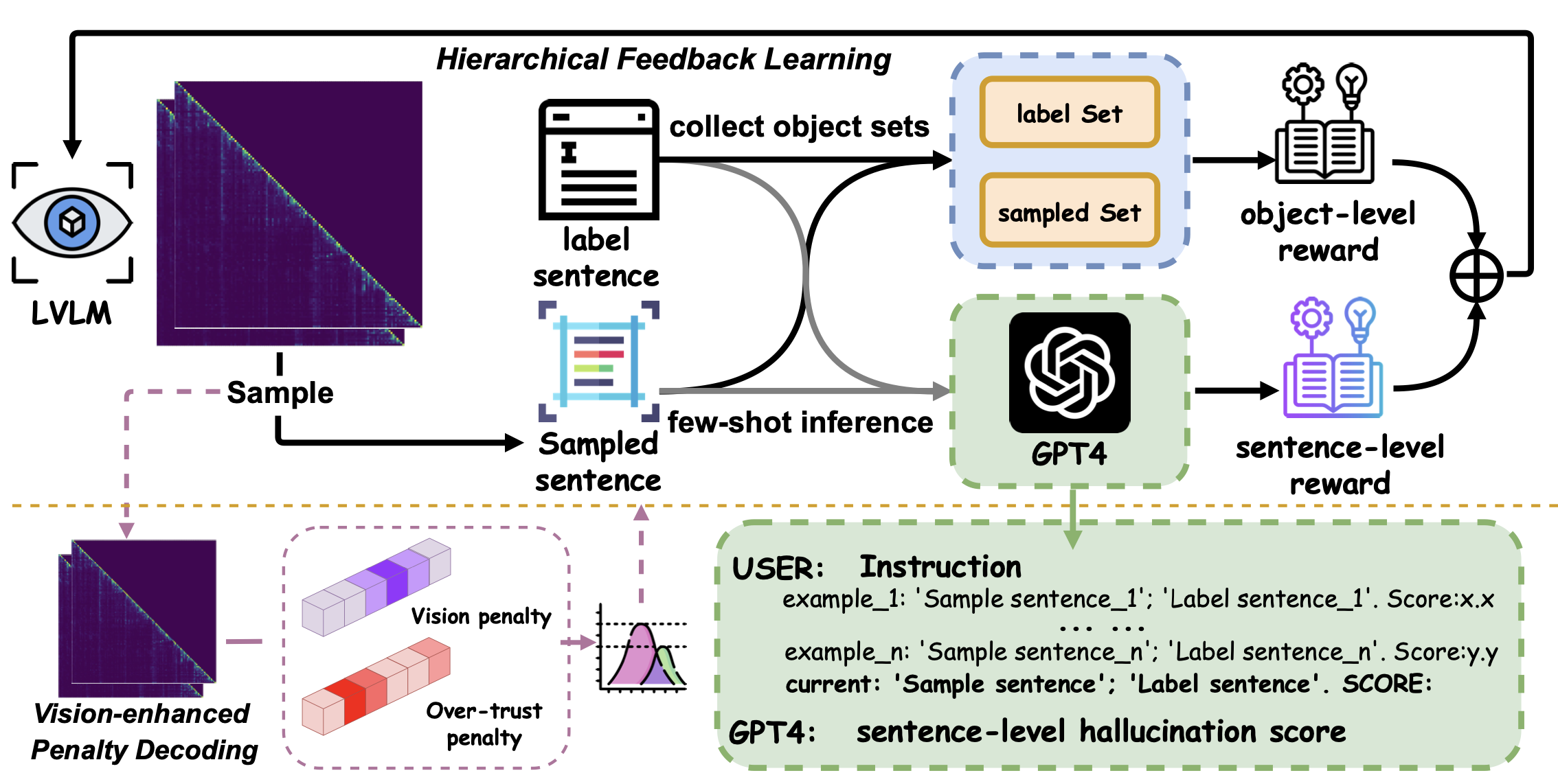 HELPD: Mitigating Hallucination of LVLMs by Hierarchical Feedback Learning with Vision-enhanced Penalty Decoding
HELPD: Mitigating Hallucination of LVLMs by Hierarchical Feedback Learning with Vision-enhanced Penalty Decoding
Fan Yuan, Chi Qin, Xiaogang Xu, Piji Li.
Conference on Empirical Methods in Natural Language Processing (EMNLP), 2024. -
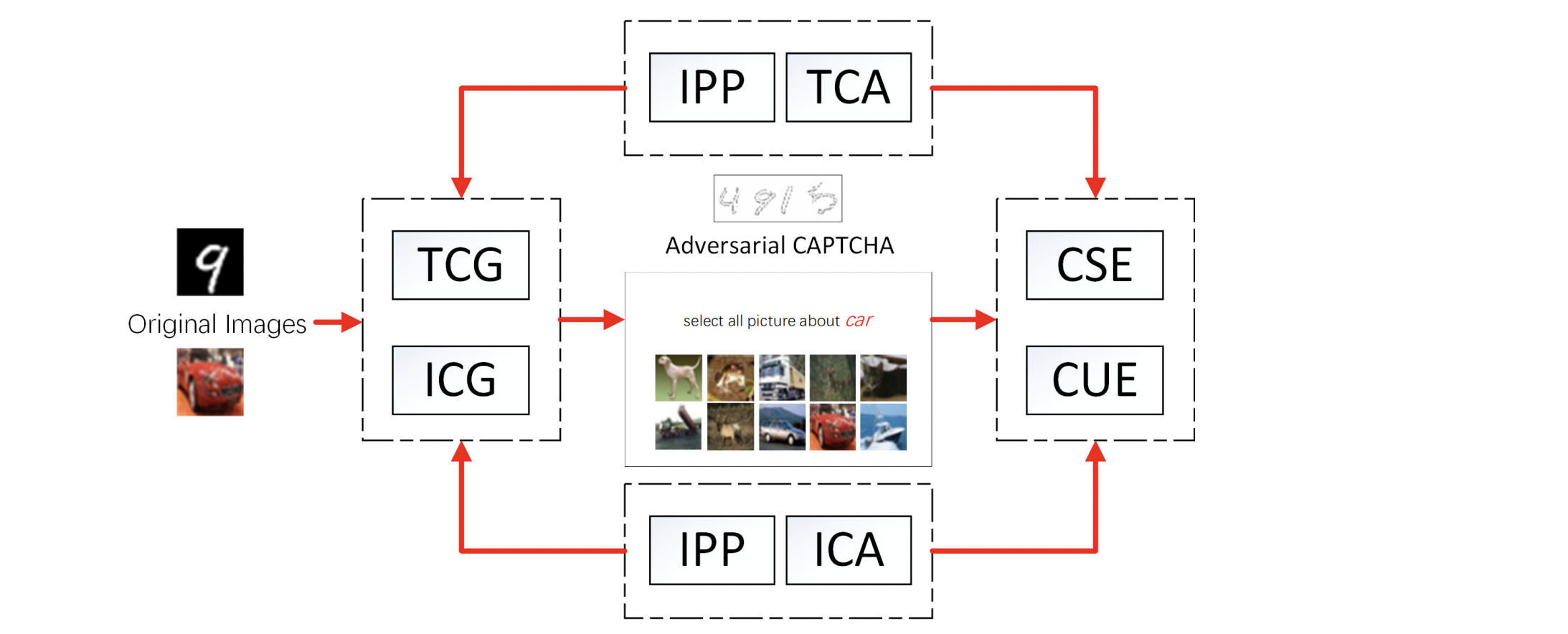 Adversarial Captchas (Applied and deployed on Alibaba's e-commerce platform)
Adversarial Captchas (Applied and deployed on Alibaba's e-commerce platform)
Chenghui Shi, Xiaogang Xu, Shouling Ji, Kai Bu, Jianhai Chen, Raheem Beyah, Ting Wang.
IEEE Transactions on Cybernetics (TCYB), 2021. -
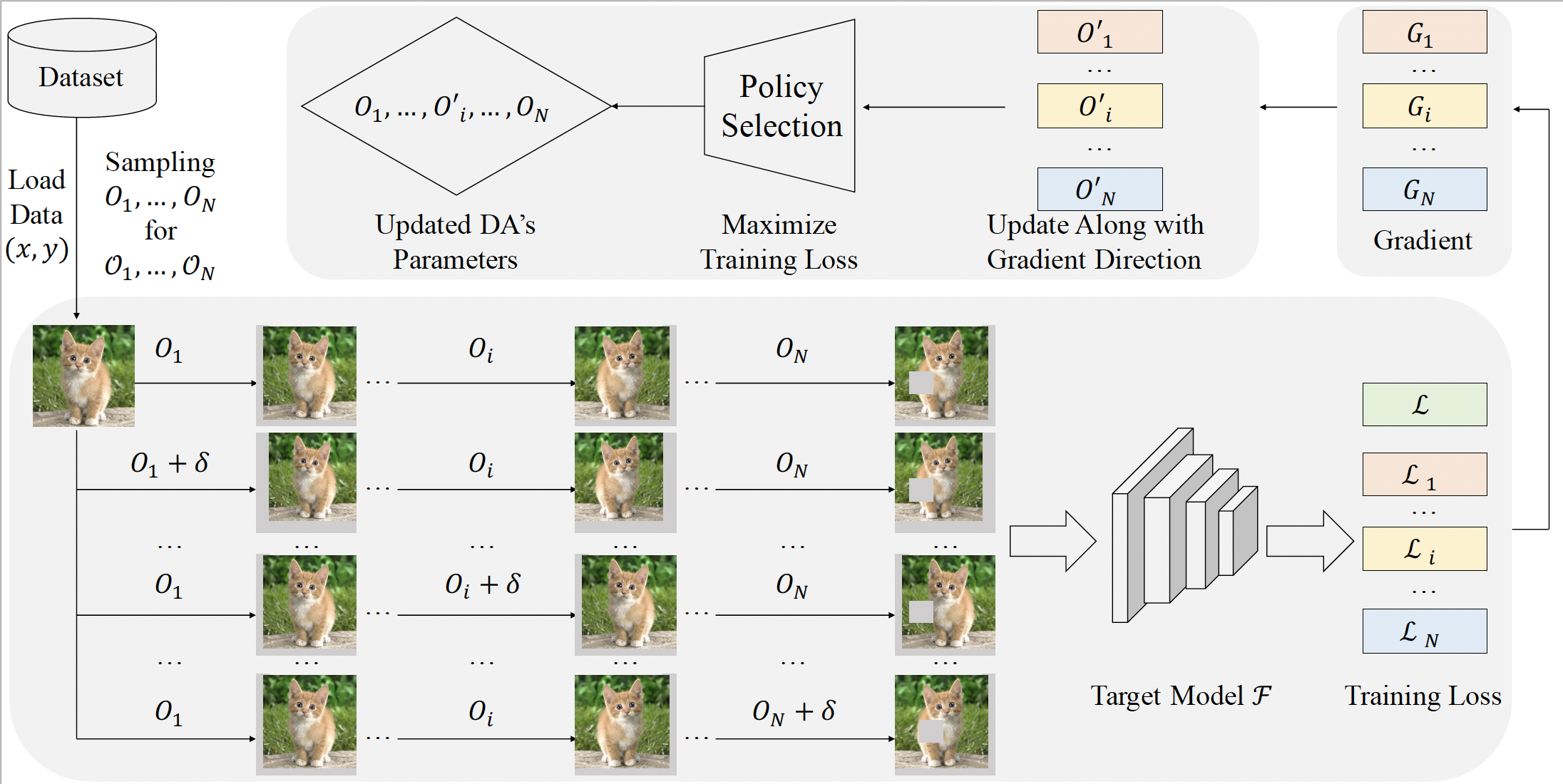 Universal Adaptive Data Augmentation
Universal Adaptive Data Augmentation
Xiaogang Xu, Hengshuang Zhao.
International Joint Conferences on Artificial Intelligence (IJCAI), 2023 (acceptance rate 15.0% (685/4566)). -
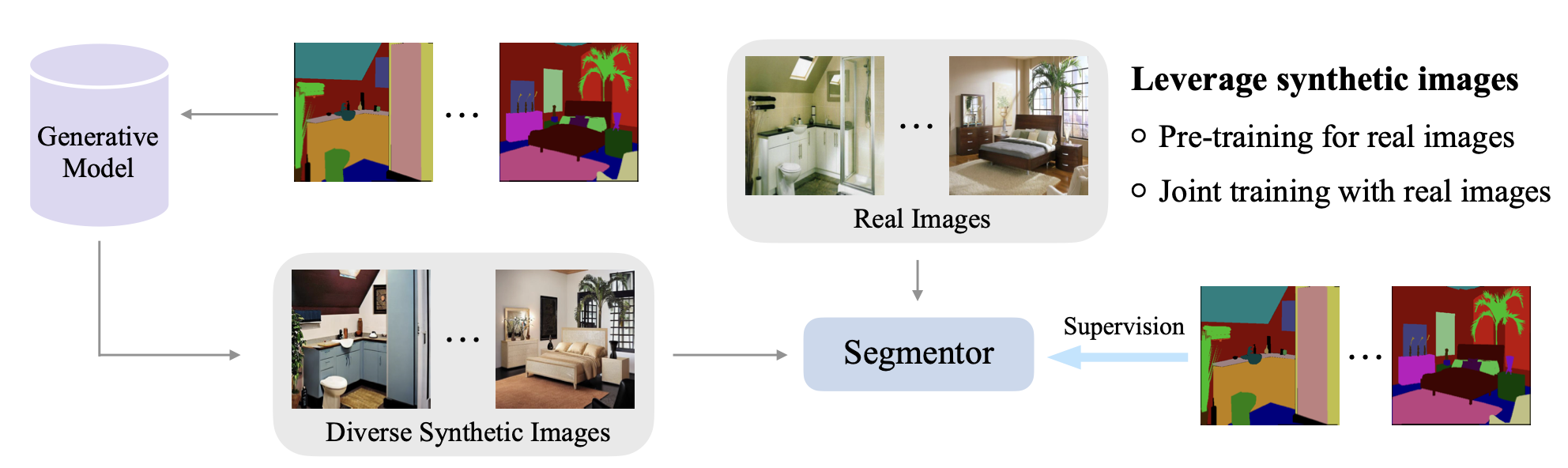 Densely Annotated Synthetic Images Make Stronger Semantic Segmentation Models
Densely Annotated Synthetic Images Make Stronger Semantic Segmentation Models
Lihe Yang, Xiaogang Xu, Bingyi Kang, Yinghuan Shi, Hengshuang Zhao.
Conference on Neural Information Processing Systems (NeurIPS), 2023, (acceptance rate 26.1% (3221/12343)). -
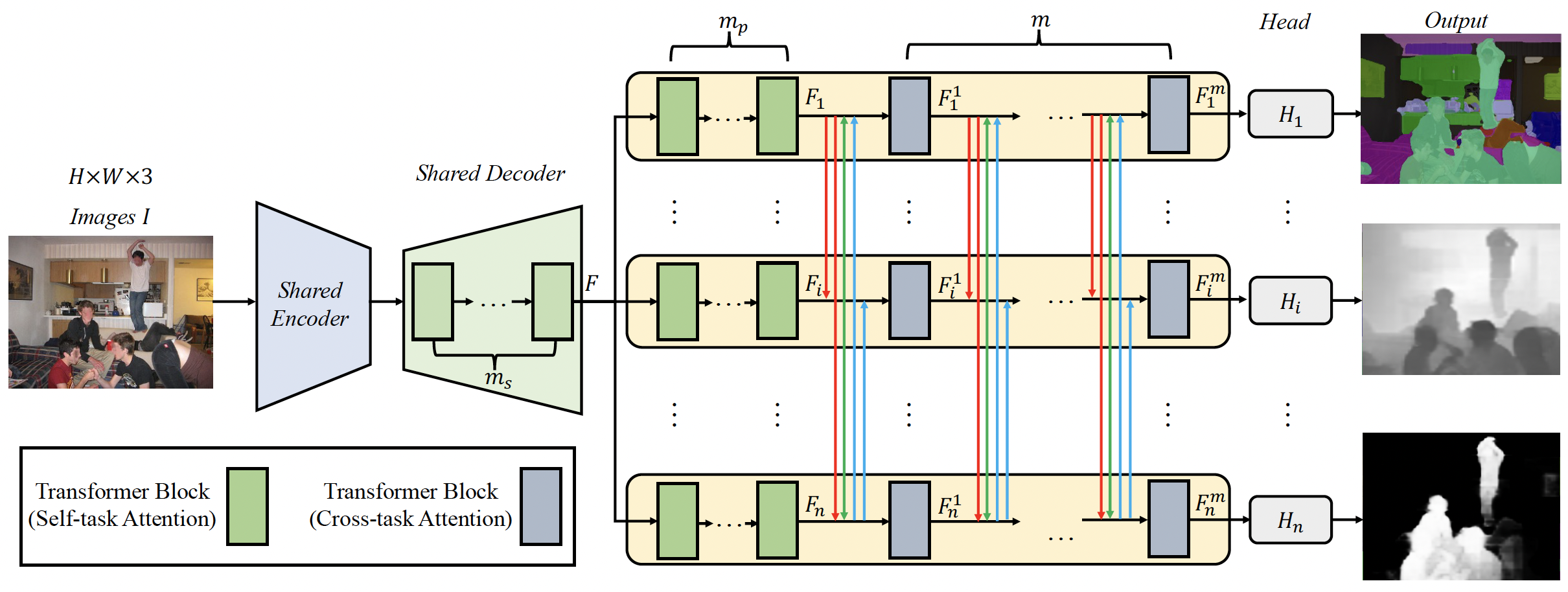 MTFormer: Multi-Task Learning via Transformer and Cross-Task Reasoning
MTFormer: Multi-Task Learning via Transformer and Cross-Task Reasoning
Xiaogang Xu, Hengshuang Zhao, Vibhav Vineet, Ser-Nam Lim, Antonio Torralba.
European Conference on Computer Vision (ECCV), 2022 (acceptance rate 19.9% (1629/8170)). -
 Dynamic divide-and-conquer adversarial training for robust semantic segmentation
Dynamic divide-and-conquer adversarial training for robust semantic segmentation
Xiaogang Xu, Hengshuang Zhao, Jiaya Jia.
IEEE International Conference on Computer Vision (ICCV), 2021 (acceptance rate 26.2% (1612/6152)). -
 Towards Unified 3D Object Detection via Algorithm and Data Unification
Towards Unified 3D Object Detection via Algorithm and Data Unification
Zhuoling Li, Xiaogang Xu, SerNam Lim, Hengshuang Zhao.
TPAMI, 2025. -
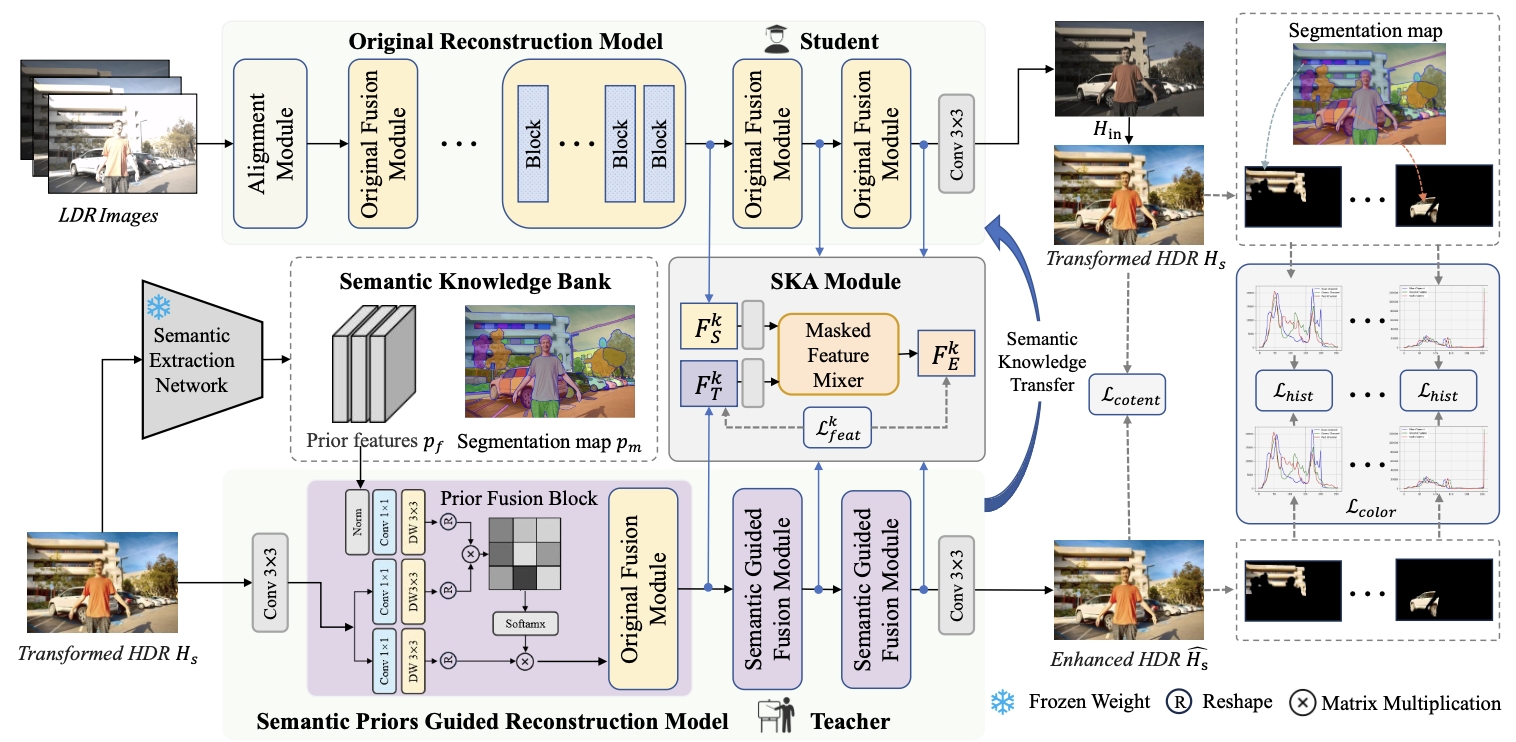 Boosting HDR Image Reconstruction via Semantic Knowledge Transfer
Boosting HDR Image Reconstruction via Semantic Knowledge Transfer
Tao Hu, Longyao Wu, Wei Dong, Peng Wu, Jinqiu Sun, Xiaogang Xu, Qingsen Yan, Yanning Zhang.
TIP, 2026. -
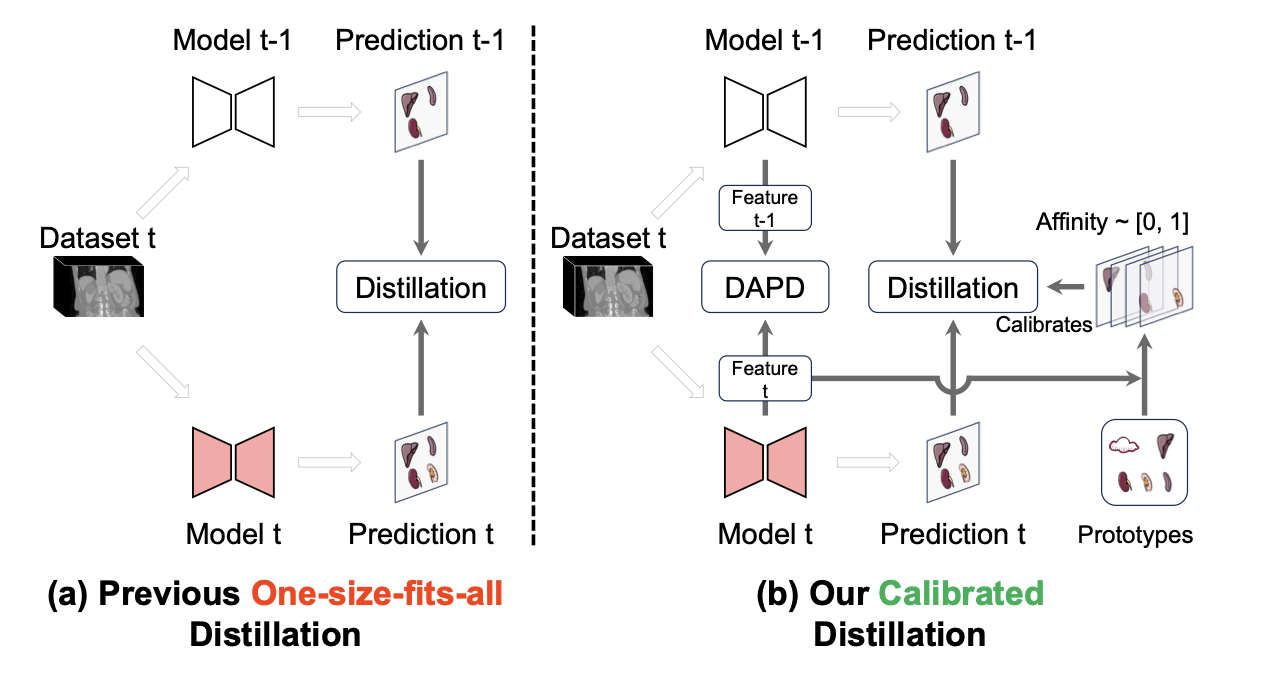 Class Incremental Medical Image Segmentation via Prototype-Guided Calibration and Dual-Aligned Distillation
Class Incremental Medical Image Segmentation via Prototype-Guided Calibration and Dual-Aligned Distillation
Shengqian Zhu, Chengrong Yu, Qiang Wang, Ying Song, Guangjun Li, Jiafei Wu, Xiaogang Xu#, Yi Zhang, Junjie Hu.
AAAI, 2026. -
Robust-R1: Degradation-Aware Reasoning for Robust Visual Understanding
Jiaqi Tang, Jianmin Chen, Wei Wei, Xiaogang Xu, Runtao Liu, Xiangyu Wu, Qipeng Xie, Jiafei Wu Wu, Lei Zhang, Qifeng Chen.
AAAI, 2026. -
 SEE: See Everything Every Time--Adaptive Brightness Adjustment for Broad Light Range Images via Events
SEE: See Everything Every Time--Adaptive Brightness Adjustment for Broad Light Range Images via Events
Yunfan Lu, Xiaogang Xu, Hao Lu, Yanlin Qian, Pengteng Li, Huizai Yao, Bin Yang, Junyi Li, Qianyi Cai, Weiyu Guo, Hui Xiong.
IJCV, 2025. -
Wan-Move: Motion-controllable Video Generation via Latent Trajectory Guidance
Ruihang Chu, Yefei He, Zhekai Chen, Shiwei Zhang, Xiaogang Xu, Bin Xia, Dingdong WANG, Hongwei Yi, Xihui Liu, Hengshuang Zhao, Yu Liu, Yingya Zhang, Yujiu Yang.
NeurIPS, 2025. -
MiCo: Multi-image Contrast for Reinforcement Visual Reasoning
Xi Chen, Mingkang Zhu, Shaoteng Liu, Xiaoyang Wu, Xiaogang Xu, Yu Liu, Xiang Bai, Hengshuang Zhao.
NeurIPS, 2025. -
 DiffCamera: Arbitrary Refocusing on Images
DiffCamera: Arbitrary Refocusing on Images
Yiyang Wang, Xi Chen, Xiaogang Xu, Yu Liu, Hengshuang Zhao.
SIGGRAPH ASIA, 2025. -
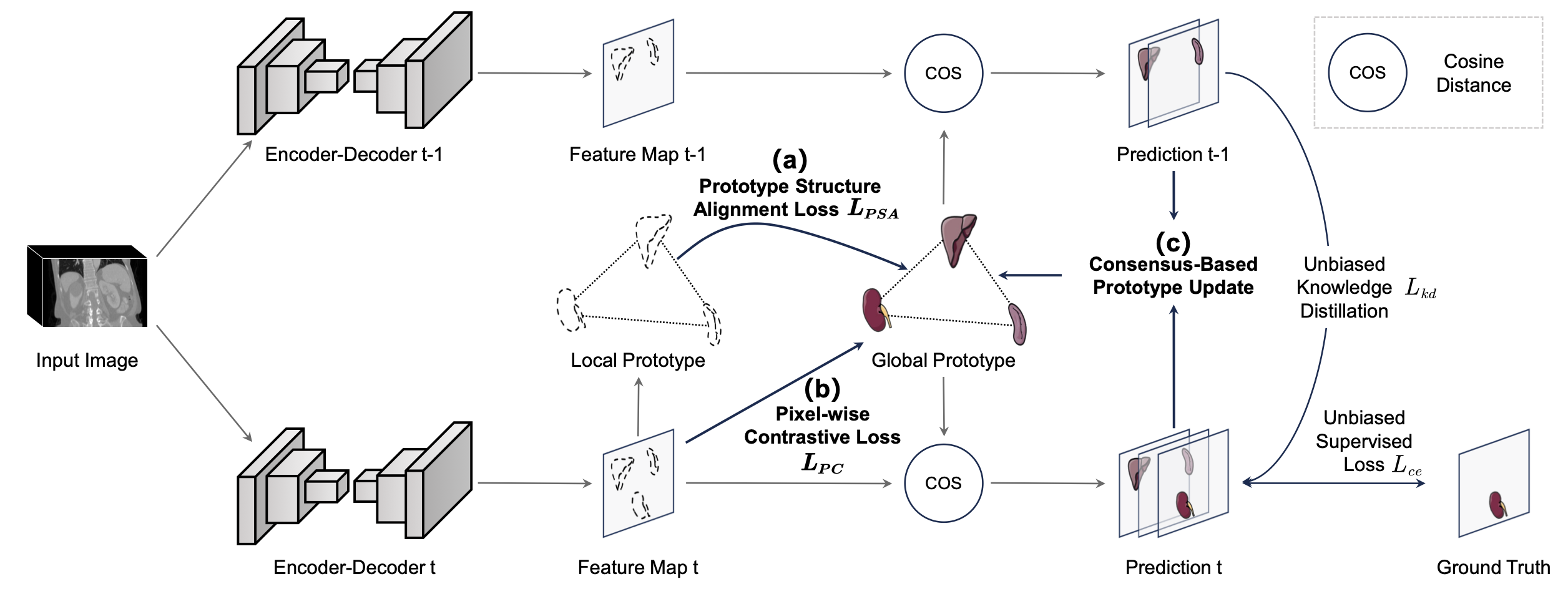 PRIME: Prototype-Driven Class Incremental Learning for Medical Image Segmentation
PRIME: Prototype-Driven Class Incremental Learning for Medical Image Segmentation
Shengqian Zhu, Chengrong Yu, Wenbo Qi, Jiafei Wu, Ying Song, Guangjun Li, Yi Zhang, Xiaogang Xu#, Junjie Hu.
ACM MM, 2025. -
 PVDD: A Practical Video Denoising Dataset with Real-World Dynamic Scenes
PVDD: A Practical Video Denoising Dataset with Real-World Dynamic Scenes
Xiaogang Xu, Yitong Yu, Nianjuan Jiang, Jiangbo Lu, Bei Yu, Jiaya Jia.
Frontiers of Computer Science, 2025. -
Geometric-Aware Low-Light Image and Video Enhancement via Depth Guidance
Yingqi Lin*, Xiaogang Xu*#, Jiafei Wu, Yan Han, Zhe Liu.
IEEE Transactions on Image Processing (TIP), 2025. -
 Boosting Diffusion-Based Text Image Super-Resolution Model Towards Generalized Real-World Scenarios
Boosting Diffusion-Based Text Image Super-Resolution Model Towards Generalized Real-World Scenarios
Chenglu Pan, Xiaogang Xu#, Ganggui Ding, Yunke Zhang, Wenbo Li, Jiarong Xu, Qingbiao Wu.
ICCV Workshop, 2025. -
 Diffusion Noise Feature: Accurate and Fast Generated Image Detection
Diffusion Noise Feature: Accurate and Fast Generated Image Detection
Yichi Zhang, Xiaogang Xu#.
ECAI, 2025. -
 CG-FedLLM: How to Compress Gradients in Federated Fune-tuning for Large Language Models
CG-FedLLM: How to Compress Gradients in Federated Fune-tuning for Large Language Models
Huiwen Wu, Xiaohan Li, Deyi Zhang, Xiaogang Xu#, Jiafei Wu, Puning Zhao, Zhe Liu.
ECAI, 2025. -
Learnable Feature Patches and Vectors for Boosting Low-light Image Enhancement without External Knowledge
Xiaogang Xu, Jiafei Wu, Qingsen Yan, Jiequan Cui, Richang Hong, Bei Yu.
ICCV, 2025. -
 Co-Painter: Fine-Grained Controllable Image Stylization via Implicit Decoupling and Adaptive Injection
Co-Painter: Fine-Grained Controllable Image Stylization via Implicit Decoupling and Adaptive Injection
Bowen Fu, Wei Wei, Jiaqi Tang, Jiangtao Nie, Yanyu Ye, Xiaogang Xu, Ying-cong Chen, Lei Zhang.
ICCV, 2025. -
DiffDoctor: Diagnosing Image Diffusion Models Before Treating
Yiyang Wang, Xi Chen, Xiaogang Xu#, Sihui Ji, Yu Liu, Yujun Shen, Hengshuang Zhao.
ICCV, 2025. -
Adversarial Attacks of Vision Tasks in the Past 10 Years: A Survey
Chiyu Zhang, Xiaogang Xu#, Jiafei Wu, Zhe Liu, Lu Zhou.
ACM Computing Surveys, 2025. -
Towards Unified 3D Object Detection via Algorithm and Data Unification
Zhuoling Li, Xiaogang Xu, SerNam Lim, Hengshuang Zhao.
TPAMI, 2025. -
FashionComposer: Compositional Fashion Image Generations
Sihui Ji, Yiyang Wang, Xi Chen, Xiaogang Xu, Hao Luo, Hengshuang Zhao.
SIGGRAPH, 2025. -
CFSynthesis: Controllable and free-view 3d human video synthesis
Liyuan Cui, Xiaogang Xu#, Wenqi Dong, Zesong Yang, Hujun Bao, Zhaopeng Cui.
ICMR, 2025. -
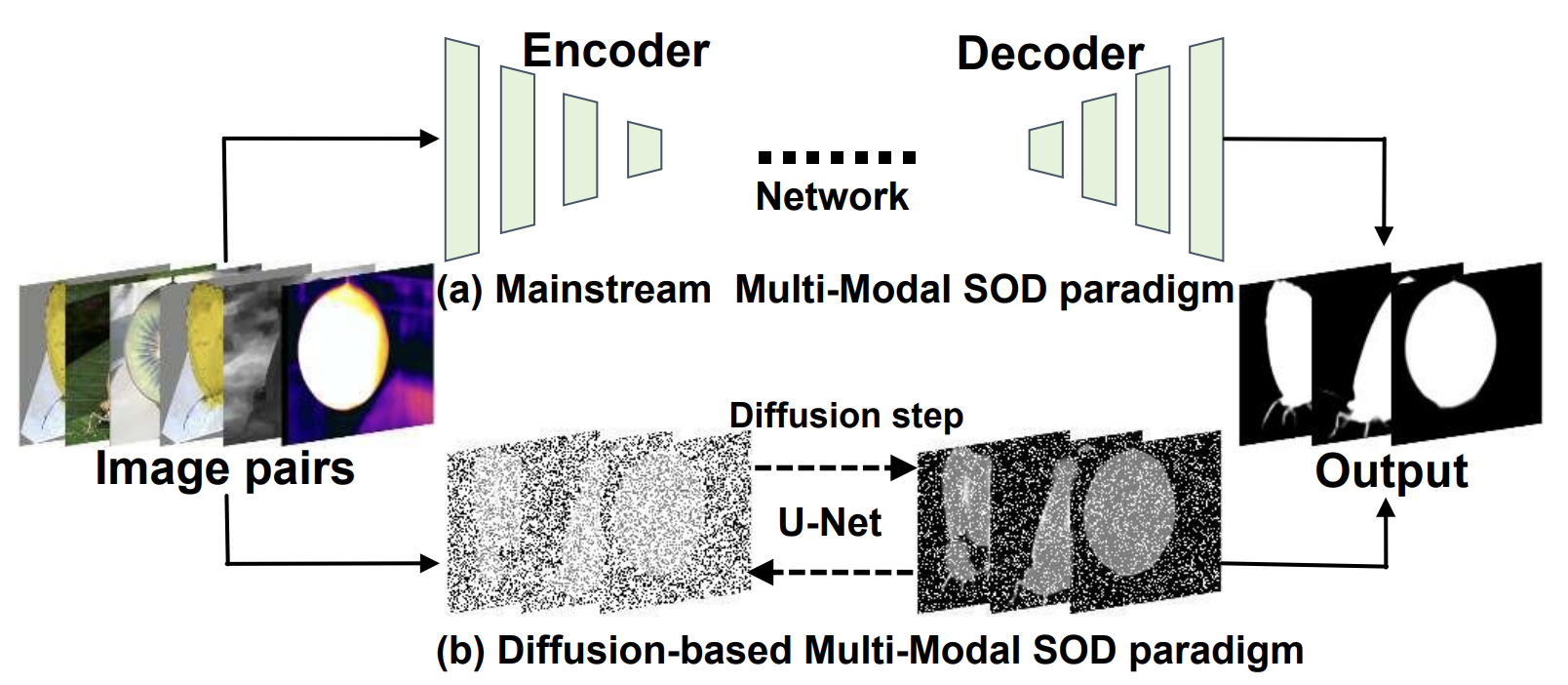 DiMSOD: A Diffusion-Based Framework for Multi-Modal Salient Object Detection
DiMSOD: A Diffusion-Based Framework for Multi-Modal Salient Object Detection
Shuo Zhang, Jiaming Huang, Wenbing Tang, Yan Wu, Terrence Hu, Xiaogang Xu, Jing Liu.
AAAI, 2025. -
DR-Encoder: Encode Low-rank Gradients with Random Prior for Large Language Models Differentially Privately
Huiwen Wu, Deyi Zhang, Xiaohan Li, Xiaogang Xu#, Jiafei Wu, Zhe Liu.
AAAI, 2025. -
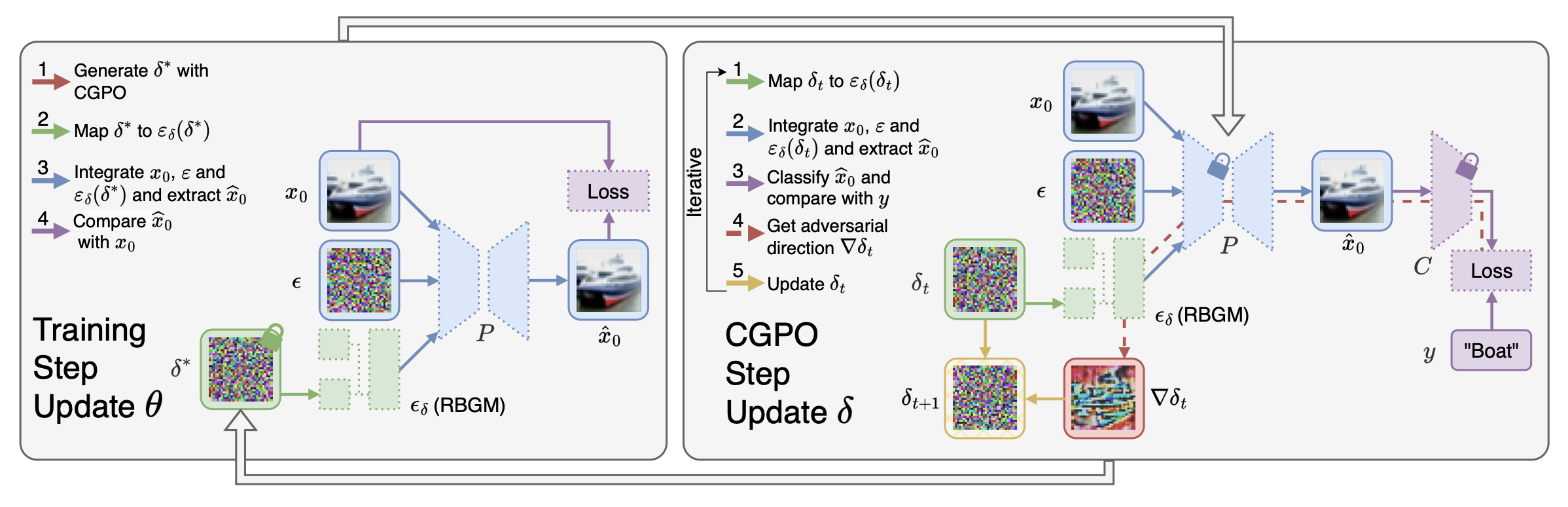 Towards Better Adversarial Purification via Adversarial Denoising Diffusion Training
Towards Better Adversarial Purification via Adversarial Denoising Diffusion Training
Yiming Liu, Kezhao Liu, Yao Xiao, Ziyi Dong, Xiaogang Xu, Pengxu Wei, Liang Lin.
ICLR, 2025. -
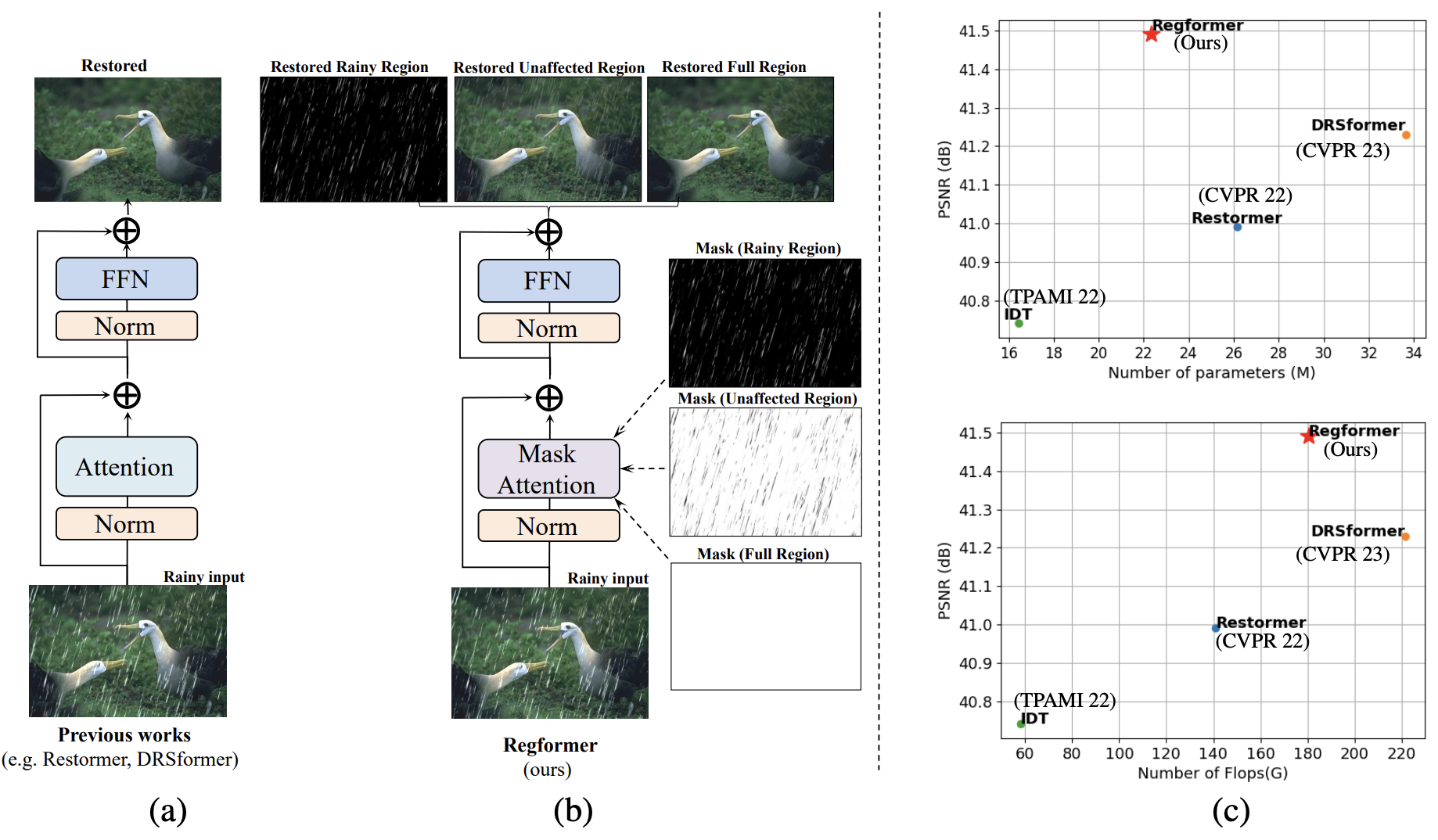 Diving Deep into Regions: Exploiting Regional Information Transformer for Single Image Deraining
Diving Deep into Regions: Exploiting Regional Information Transformer for Single Image Deraining
Baiang Li, Zhao Zhang, Huan Zheng, Xiaogang Xu#, Yanyan Wei, Jingyi Zhang, Jicong Fan, Meng Wang.
TMM, 2025. -
Low-Light Video Enhancement via Spatial-Temporal Consistent Decomposition
Xiaogang Xu, Kun Zhou, Tao Hu, Jiafei Wu, Ruixing Wang, Hao Peng, Bei Yu.
IJCAI, 2025. -
LARM: Large Auto-Regressive Model for Long-Horizon Embodied Intelligence
Zhuoling Li, Xiaogang Xu, Zhenhua Xu, SerNam Lim, Hengshuang Zhao.
ICML, 2025. -
 Sagiri: Low Dynamic Range Image Enhancement with Generative Diffusion Prior
Sagiri: Low Dynamic Range Image Enhancement with Generative Diffusion Prior
Baiang Li, Sizhuo Ma, Yanhong Zeng, Xiaogang Xu, Youqing Fang, Zhao Zhang, Jian Wang, Kai Chen.
ICCP, 2025. -
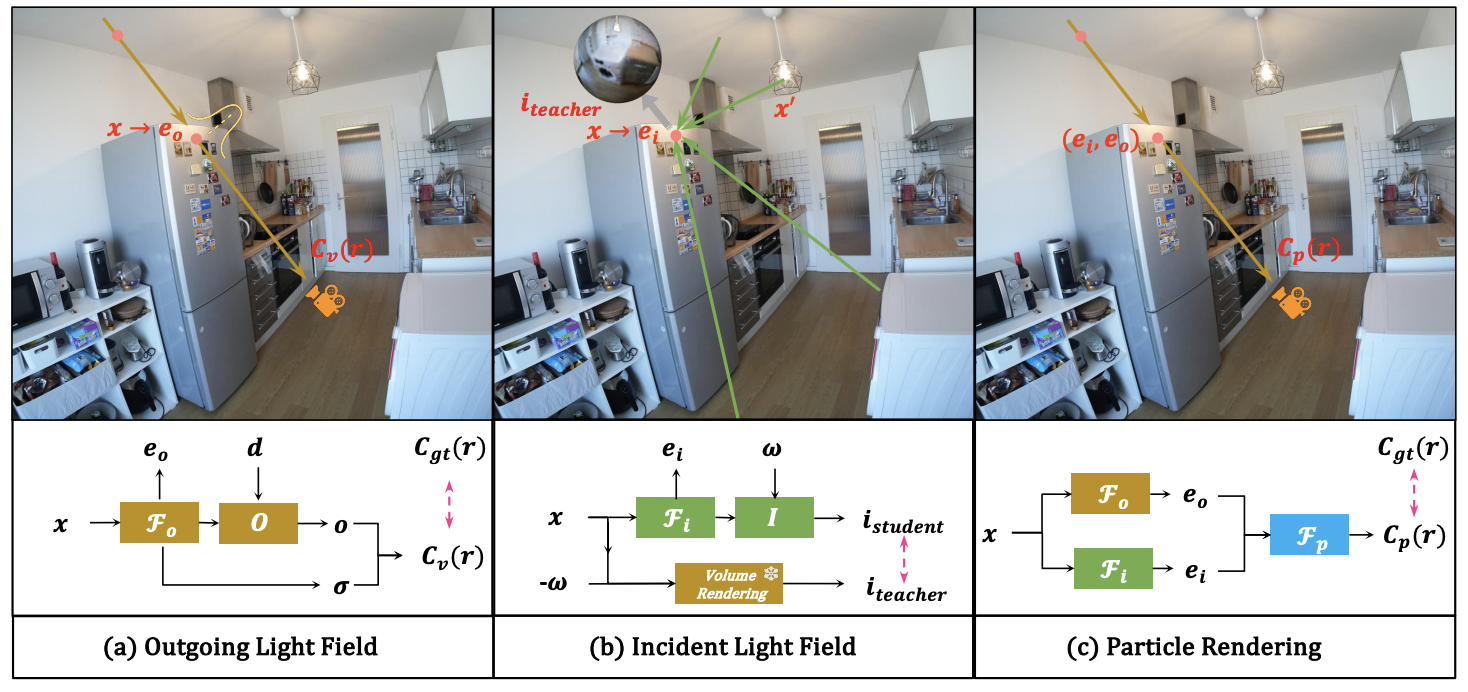 Particle Rendering: Implicitly Aggregating Incident and Outgoing Light Fields for Novel View Synthesis
Particle Rendering: Implicitly Aggregating Incident and Outgoing Light Fields for Novel View Synthesis
Tao Hu, Zhiwen Yan, Xiaogang Xu, Gim Hee Lee.
3DV, 2025. -
HELPD: Mitigating Hallucination of LVLMs by Hierarchical Feedback Learning with Vision-enhanced Penalty Decoding
Fan Yuan, Chi Qin, Xiaogang Xu, Piji Li.
Conference on Empirical Methods in Natural Language Processing (EMNLP), 2024. -
Parametric Linear Blend Skinning Model for Multiple-Shape 3D Garments
Xipeng Chen, Guangrun Wang, Xiaogang Xu, Philip Torr, Liang Lin.
IEEE Transactions on Visualization and Computer Graphics (TVCG), 2024. -
Hawk: Learning to Understand Open-World Video Anomalies
Jiaqi Tang, Hao Lu, Ruizheng Wu, Xiaogang Xu, Ke Ma, Cheng Fang, Bin Guo, Jiangbo Lu, Qifeng Chen, Ying-Cong Chen.
Conference on Neural Information Processing Systems (NeurIPS), 2024, (acceptance rate 25.8%). -
Depth Anything V2
Lihe Yang, Bingyi Kang, Zilong Huang, Zhen Zhao, Xiaogang Xu, Jiashi Feng, Hengshuang Zhao.
Conference on Neural Information Processing Systems (NeurIPS), 2024, (acceptance rate 25.8%). -
 Unveiling Advanced Frequency Disentanglement Paradigm for Low-Light Image Enhancement
Unveiling Advanced Frequency Disentanglement Paradigm for Low-Light Image Enhancement
Kun Zhou, Xinyu Lin, Wenbo Li, Xiaogang Xu, Yuanhao Cai, Zhonghang Liu, Xiaoguang Han, Jiangbo Lu.
European Conference on Computer Vision (ECCV), 2024, (acceptance rate 18% (2395/12600)). -
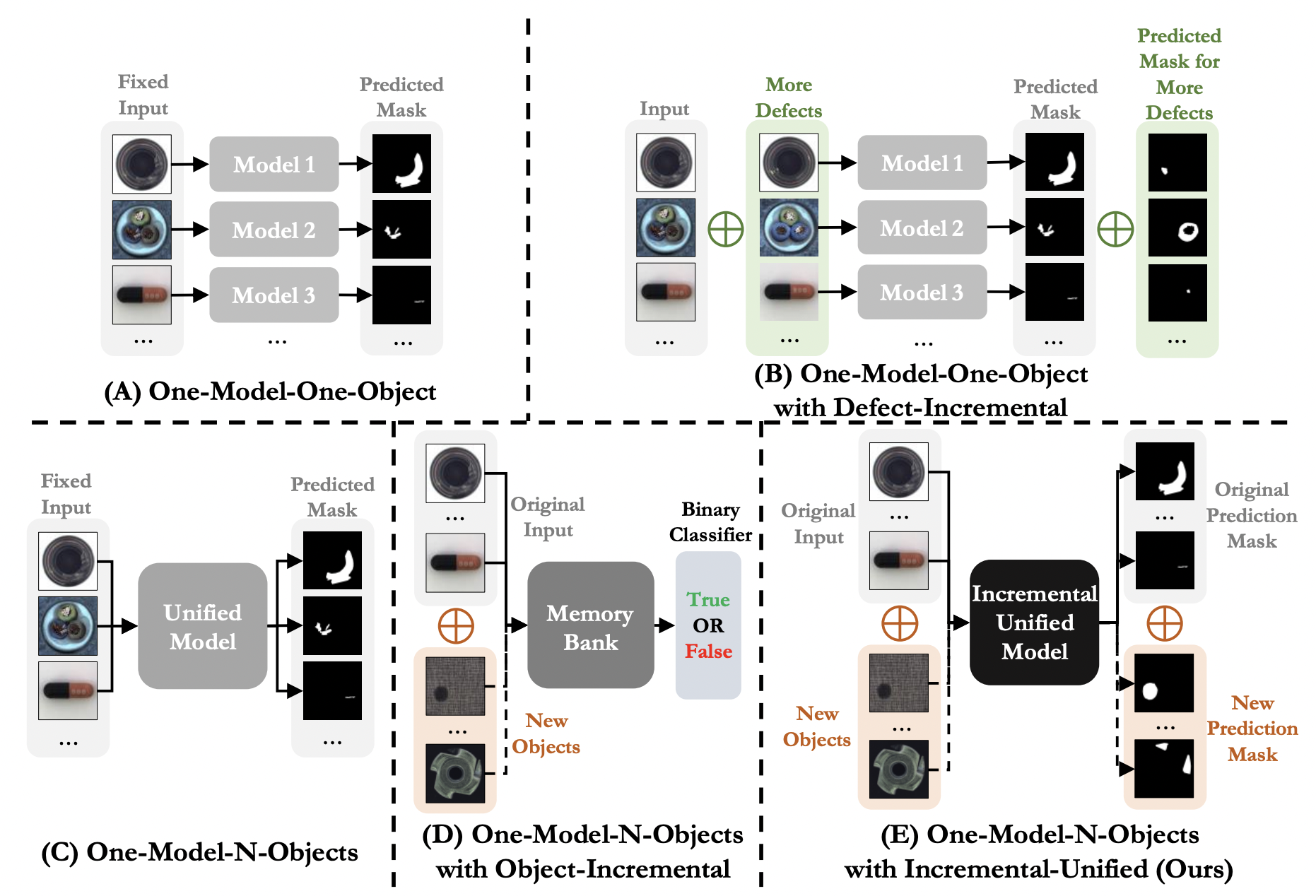 An Incremental Unified Framework for Small Defect Inspection
An Incremental Unified Framework for Small Defect Inspection
Jiaqi Tang, Hao Lu, Xiaogang Xu, Ruizheng Wu, Sixing Hu, Tong Zhang, Tsz Wa Cheng, Ming Ge, Yingcong Chen, Fugee Tsung.
European Conference on Computer Vision (ECCV), 2024, (acceptance rate 18% (2395/12600)). -
 Refine, Discriminate and Align: Stealing Encoders via Sample-Wise Prototypes and Multi-Relational Extraction
Refine, Discriminate and Align: Stealing Encoders via Sample-Wise Prototypes and Multi-Relational Extraction
Shuchi Wu, Chuan Ma, Kang Wei, Xiaogang Xu, Ming Ding, Yuwen Qian, Di Xiao, Tao Xiang.
European Conference on Computer Vision (ECCV), 2024, (acceptance rate 18% (2395/12600)). -
Towards Efficient Large-Scale Language-3D Representation Learning
Shentong Mo, Xiaogang Xu, Tongzhou Wang, Antonio Torralba, Shuang Li.
International Conference on Machine Learning (ICML), 2024, (acceptance rate 27.5% (2609/9473)). -
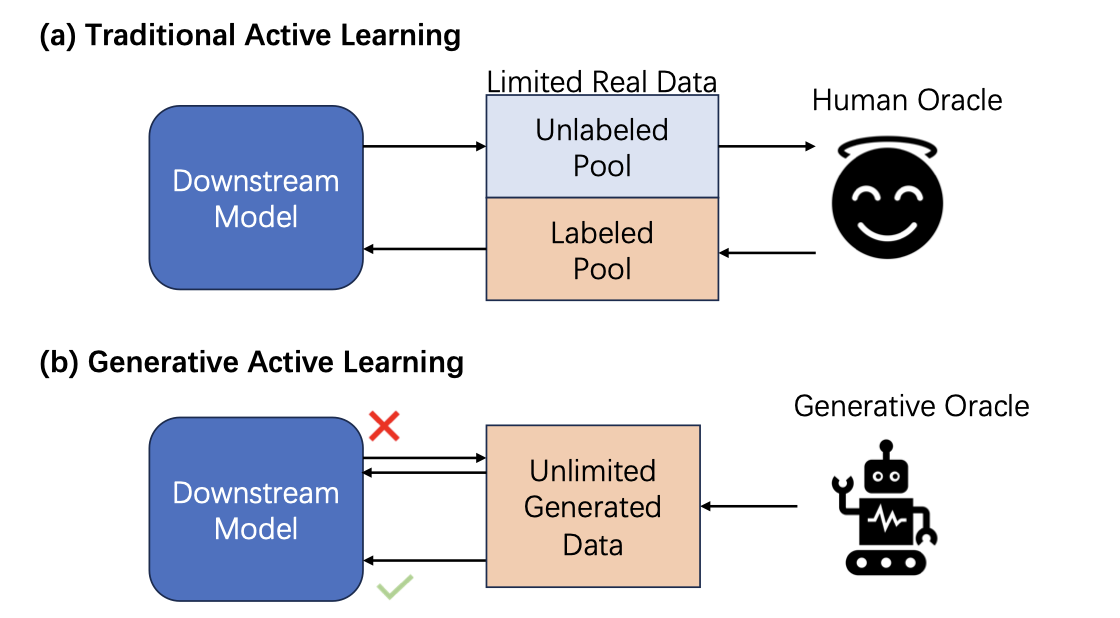 Generative Active Learning for Long-tailed Instance Segmentation
Generative Active Learning for Long-tailed Instance Segmentation
Muzhi Zhu, Chengxiang Fan, Hao Chen, Yang Liu, Weian Mao, Xiaogang Xu, Chunhua Shen.
International Conference on Machine Learning (ICML), 2024, (acceptance rate 27.5% (2609/9473)). -
Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data
Lihe Yang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, Hengshuang Zhao.
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024, (acceptance rate 23.6% (2719/11532), also accepted by CVPR 2024 Demo Track). -
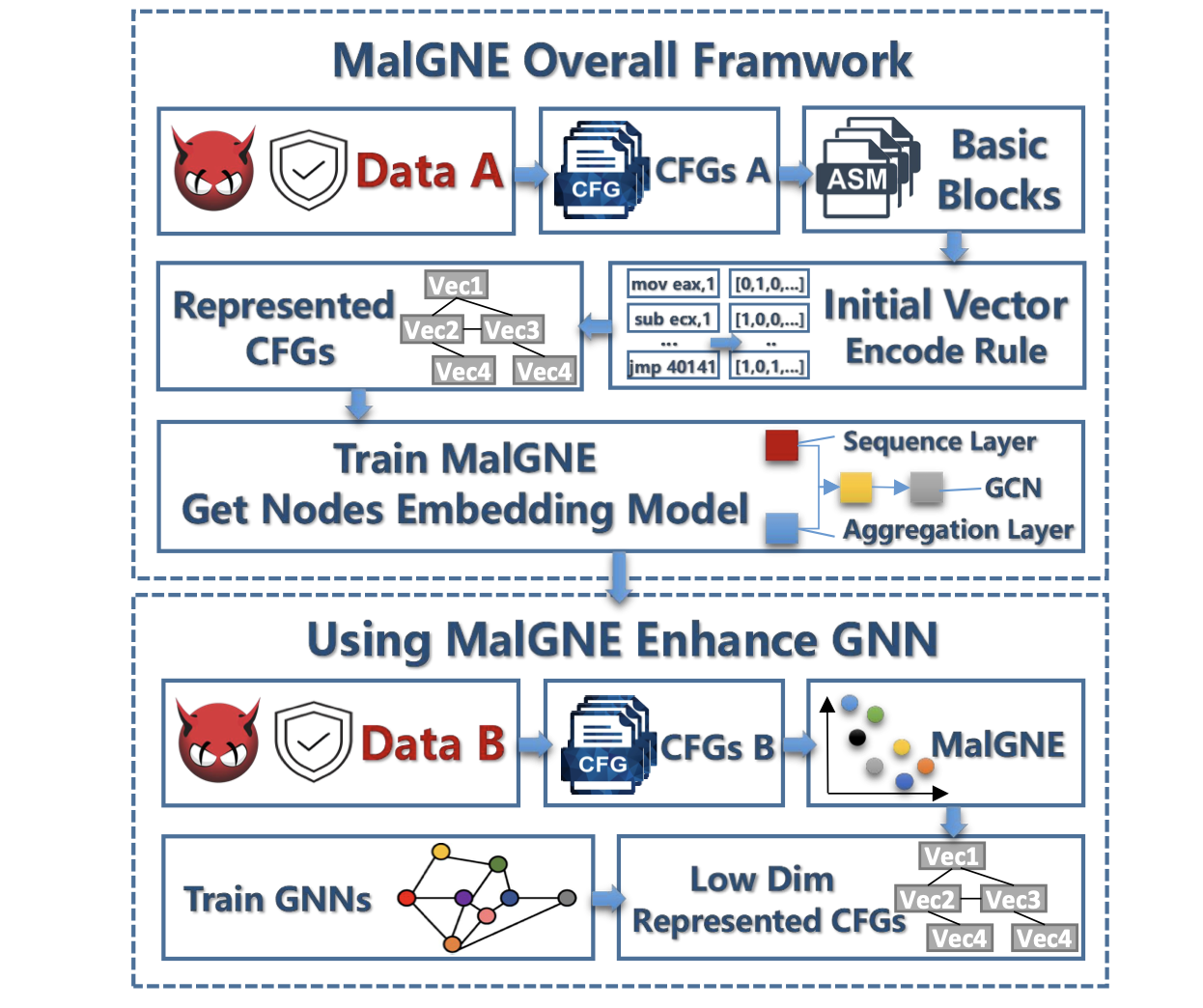 MalGNE: Enhancing the Performance and Efficiency of CFG-based Malware Detector by Graph Node Embedding in Low Dimension Space
MalGNE: Enhancing the Performance and Efficiency of CFG-based Malware Detector by Graph Node Embedding in Low Dimension Space
Hao Peng, Jieshuai Yang, Dandan Zhao, Xiaogang Xu, Yuwen Pu, Jianmin Han, Xing Yang, Ming Zhong, Shouling Ji.
IEEE Transactions on Information Forensics and Security , 2024.[Paper] Code
-
LucidDreamer: Towards High-Fidelity Text-to-3D Generation via Interval Score Matching
Yixun Liang, Xin Yang, Jiantao Lin, Haodong Li, Xiaogang Xu, Yingcong Chen.
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024, (Highlight, acceptance rate 2.8% (324/11532)). -
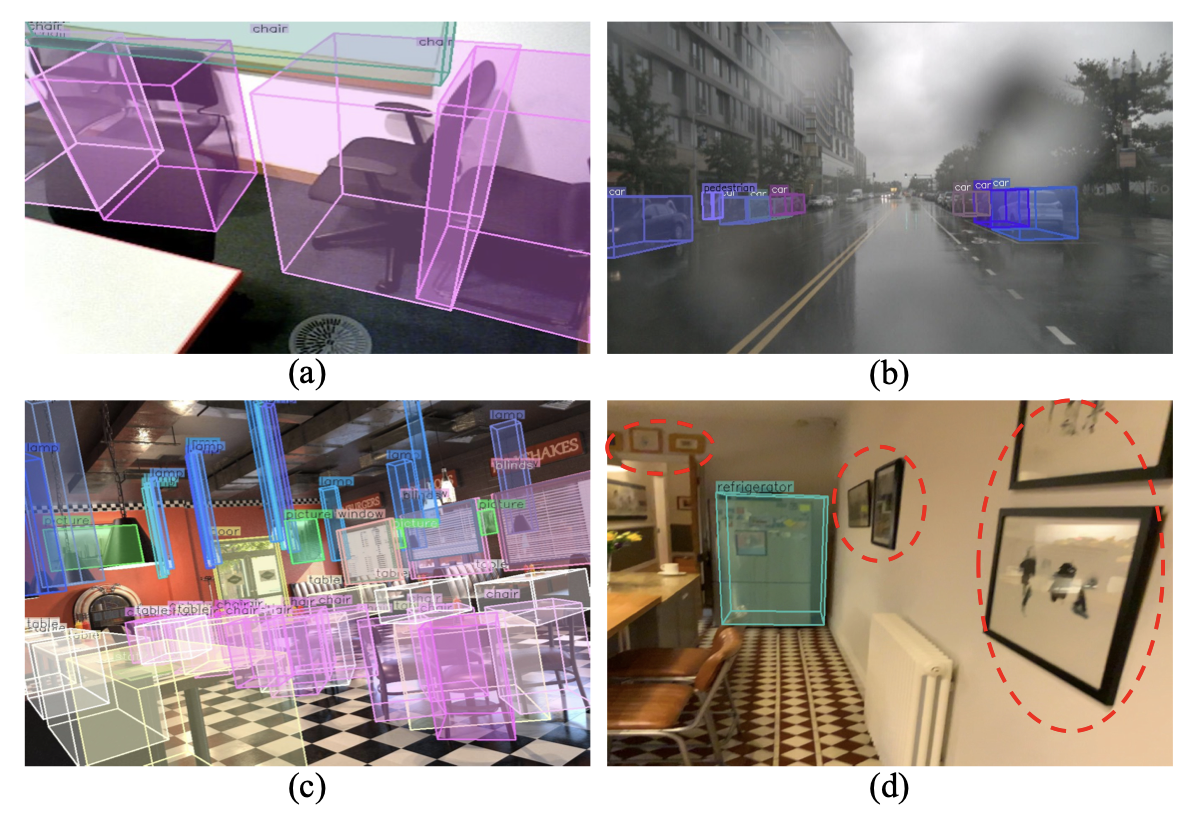 UniMODE: Universal Monocular 3D Object Detection
UniMODE: Universal Monocular 3D Object Detection
Zhuoling Li, Xiaogang Xu, Ser-Nam Lim, Hengshuang Zhao.
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024, (Highlight, acceptance rate 2.8% (324/11532)). -
Boosting Image Restoration via Priors from Pre-trained Models
Xiaogang Xu, Shu Kong, Tao Hu, Zhe Liu, Hujun Bao.
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024, (acceptance rate 23.6% (2719/11532)). -
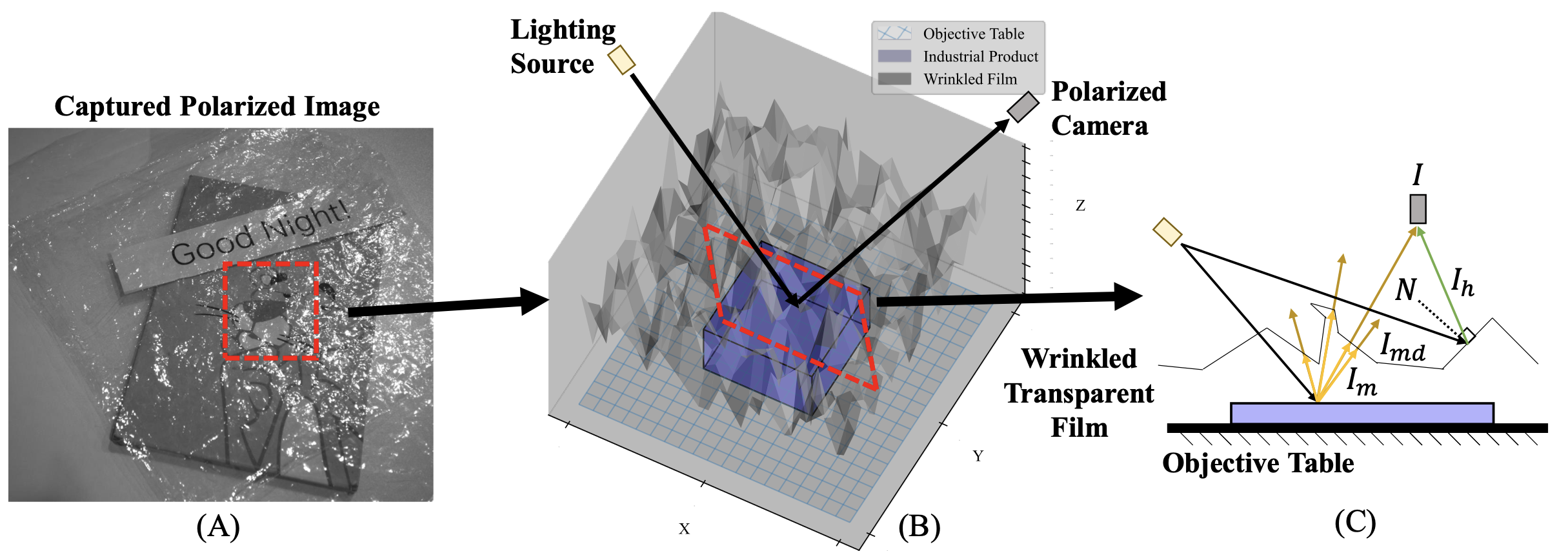 Learning to Remove Wrinkled Transparent Film with Polarized Prior
Learning to Remove Wrinkled Transparent Film with Polarized Prior
Jiaqi Tang, Ruizheng Wu, Xiaogang Xu, Sixing Hu, Ying-Cong Chen.
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024, (acceptance rate 23.6% (2719/11532)). -
S2WAT: Image Style Transfer via Hierarchical Vision Transformer using Strips Window Attention
Chiyu Zhang, Xiaogang Xu#, Lei Wang, Zaiyan Dai, Jun Yang.
AAAI Conference on Artificial Intelligence (AAAI), 2024, (acceptance rate 26.1% (2342/9862)). -
Densely Annotated Synthetic Images Make Stronger Semantic Segmentation Models
Lihe Yang, Xiaogang Xu, Bingyi Kang, Yinghuan Shi, Hengshuang Zhao.
Conference on Neural Information Processing Systems (NeurIPS), 2023, (acceptance rate 26.1% (3221/12343)). -
CorresNeRF: Image Correspondence Priors for Neural Radiance Fields
Yixing Lao, Xiaogang Xu, Xihui Liu, Hengshuang Zhao.
Conference on Neural Information Processing Systems (NeurIPS), 2023, (acceptance rate 26.1% (3221/12343)). -
Photo-Realistic Out-of-domain GAN inversion via Invertibility Decomposition
Xin Yang, Xiaogang Xu#, Yingcong Chen#.
IEEE International Conference on Computer Vision (ICCV), 2023, (acceptance rate 26.8% (2162/8068)). -
Lighting up NeRF via Unsupervised Decomposition and Enhancement
Haoyuan Wang, Xiaogang Xu, Ke Xu, Rynson Lau.
IEEE International Conference on Computer Vision (ICCV), 2023, (acceptance rate 26.8% (2162/8068)). -
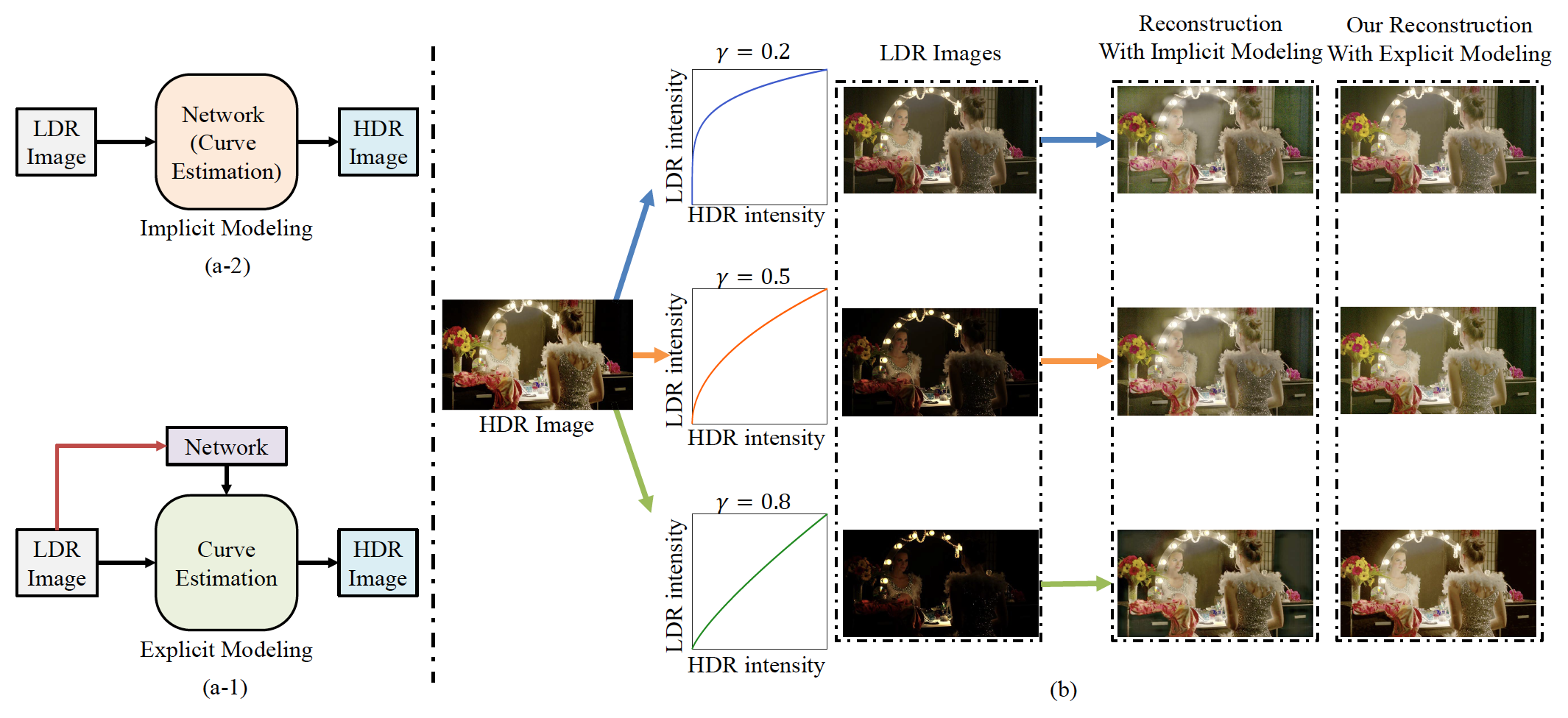 High Dynamic Range Image Reconstruction via Deep Explicit Polynomial Curve Estimation
High Dynamic Range Image Reconstruction via Deep Explicit Polynomial Curve Estimation
Jiaqi Tang, Xiaogang Xu, Sixing Hu, Yingcong Chen.
European Conference on Artificial Intelligence (ECAI), 2023 (acceptance rate 24.0% (391/1631)). -
Low‑light Image Enhancement via Structure Modeling and Guidance
Xiaogang Xu, Ruixing Wang, Jiangbo Lv.
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2023 (acceptance rate 25.8% (2340/9155)). -
TriVol: Point Cloud Rendering Via Triple Volumes
Tao Hu*, Xiaogang Xu*, Ruihang Chu, Jiaya Jia.
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2023 (acceptance rate 25.8% (2340/9155)). -
Point2Pix: Photo‑Realistic Point Cloud Rendering via Neural Radiance Fields
Tao Hu, Xiaogang Xu#, Shu Liu, Jiaya Jia.
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2023 (acceptance rate 25.8% (2340/9155)). -
Deep Parametric 3D Filters for Joint Video Denoising and Illumination Enhancement in Video Super Resolution
Xiaogang Xu, Ruixing Wang, Chi-Wing Fu, Jiaya Jia.
AAAI Conference on Artificial Intelligence (AAAI), 2023 Oral (acceptance rate 19.6% (1721/8777)). -
Conditional Temporal Variational AutoEncoder for Action Video Prediction
Xiaogang Xu, Yi Wang, Liwei Wang, Bei Yu, Jiaya Jia.
International Journal of Computer Vision (IJCV), 2023. -
Universal Adaptive Data Augmentation
Xiaogang Xu, Hengshuang Zhao.
International Joint Conferences on Artificial Intelligence (IJCAI), 2023 (acceptance rate 15.0% (685/4566)). -
MTFormer: Multi-Task Learning via Transformer and Cross-Task Reasoning
Xiaogang Xu, Hengshuang Zhao, Vibhav Vineet, Ser-Nam Lim, Antonio Torralba.
European Conference on Computer Vision (ECCV), 2022 (acceptance rate 19.9% (1629/8170)). -
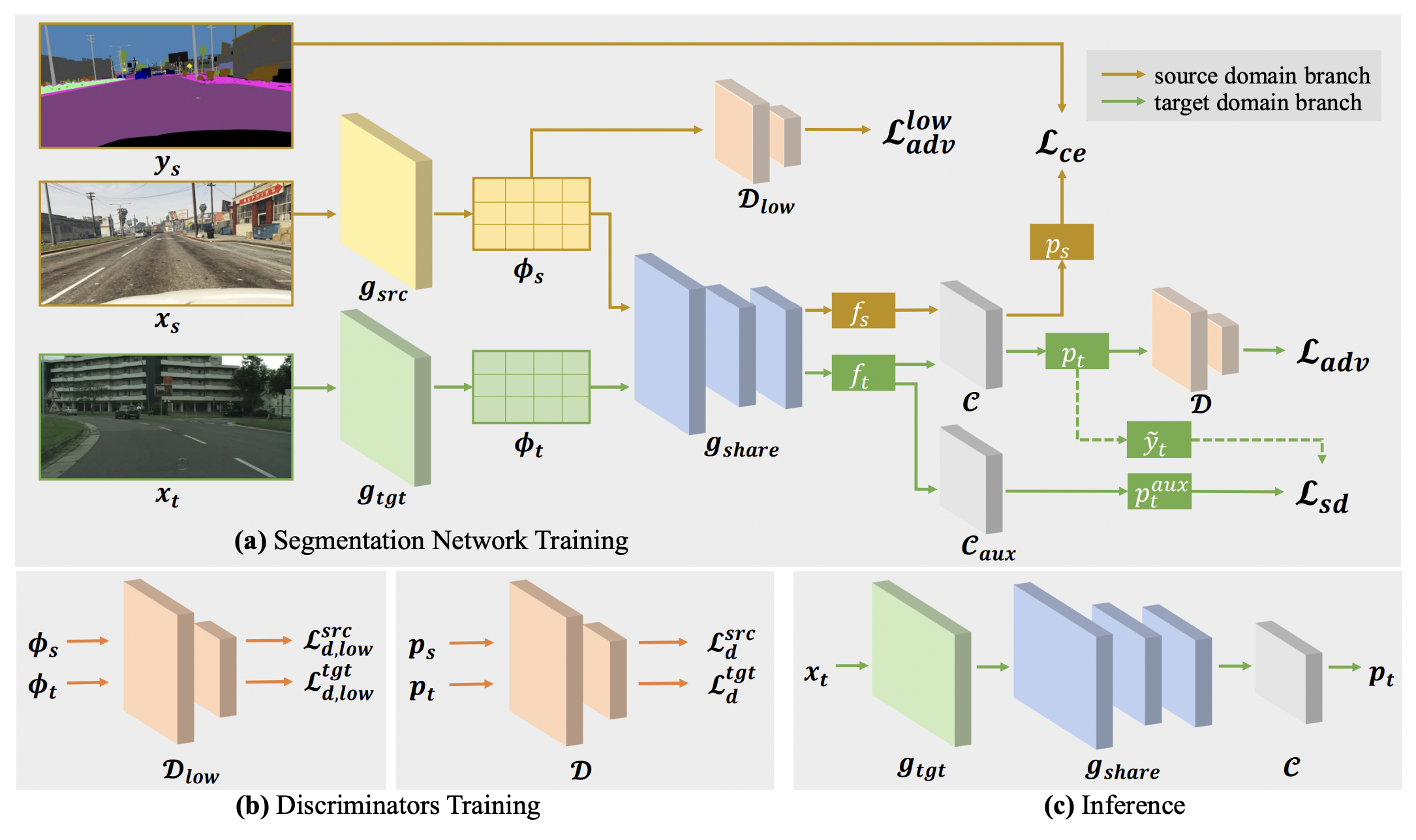 DecoupleNet: Decoupled Network for Domain Adaptive Semantic Segmentation
DecoupleNet: Decoupled Network for Domain Adaptive Semantic Segmentation
Xin Lai, Zhuotao Tian, Xiaogang Xu, Yingcong Chen, Shu Liu, Hengshuang Zhao, Liwei Wang, Jiaya Jia.
European Conference on Computer Vision (ECCV), 2022 (acceptance rate 19.9% (1629/8170)). -
SNR-Aware Low-light Image Enhancement
Xiaogang Xu, Ruixing Wang, Chi-Wing Fu, Jiaya Jia.
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2022 (acceptance rate 25.3% (2067/8161)). -
Hierarchical Image Generation via Transformer-Based Sequential Patch Selection
Xiaogang Xu, Ning Xu.
AAAI Conference on Artificial Intelligence (AAAI), 2022 (acceptance rate 15.0% (1349/9020)). -
Dynamic divide-and-conquer adversarial training for robust semantic segmentation
Xiaogang Xu, Hengshuang Zhao, Jiaya Jia.
IEEE International Conference on Computer Vision (ICCV), 2021 (acceptance rate 26.2% (1612/6152)). -
Seeing Dynamic Scene in the Dark: A High-Quality Video Dataset with Mechatronic Alignment
Ruixing Wang*, Xiaogang Xu*, Chi-Wing Fu, Jiangbo Lu, Bei Yu, Jiaya Jia.
IEEE International Conference on Computer Vision (ICCV), 2021 (acceptance rate 26.2% (1612/6152)). -
Text-Guided Human Image Manipulation via Image-Text Shared Space
Xiaogang Xu, Yingcong Chen, Jiaya Jia.
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2021. -
Adversarial Captchas (Applied and deployed on Alibaba's e-commerce platform)
Chenghui Shi, Xiaogang Xu, Shouling Ji, Kai Bu, Jianhai Chen, Raheem Beyah, Ting Wang.
IEEE Transactions on Cybernetics (TCYB), 2021. -
 Self-Supervised 3D Mesh Reconstruction from Single Images
Self-Supervised 3D Mesh Reconstruction from Single Images
Tao Hu, Liwei Wang, Xiaogang Xu, Shu Liu, Jiaya Jia.
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2021 (acceptance rate 23.7% (1661/7015)). -
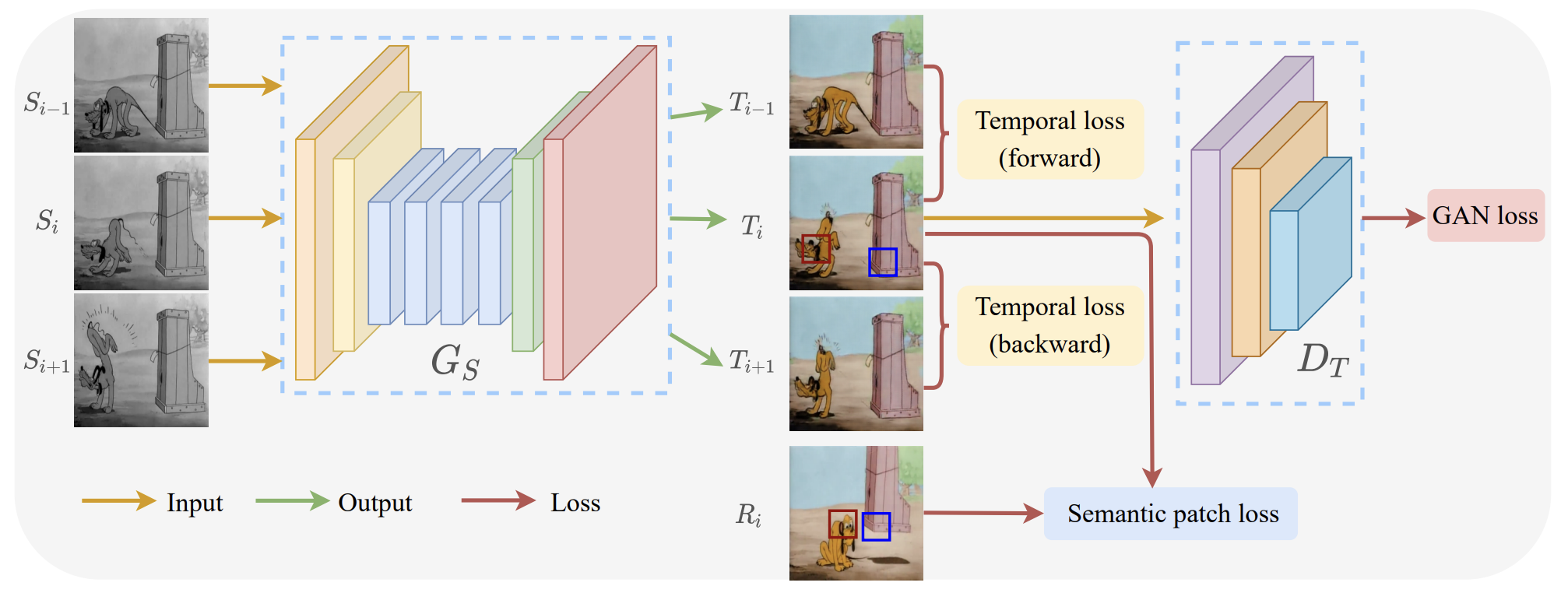 Semantic-Aware Video Color Style Transfer based on Temporal Consistent Sparse Patch Constraint
Semantic-Aware Video Color Style Transfer based on Temporal Consistent Sparse Patch Constraint
Yaxin Liu, Xiaoyan Zhang, Xiaogang Xu#.
IEEE International Conference on Multimedia and Expo (ICME), 2021.[Paper] Code
-
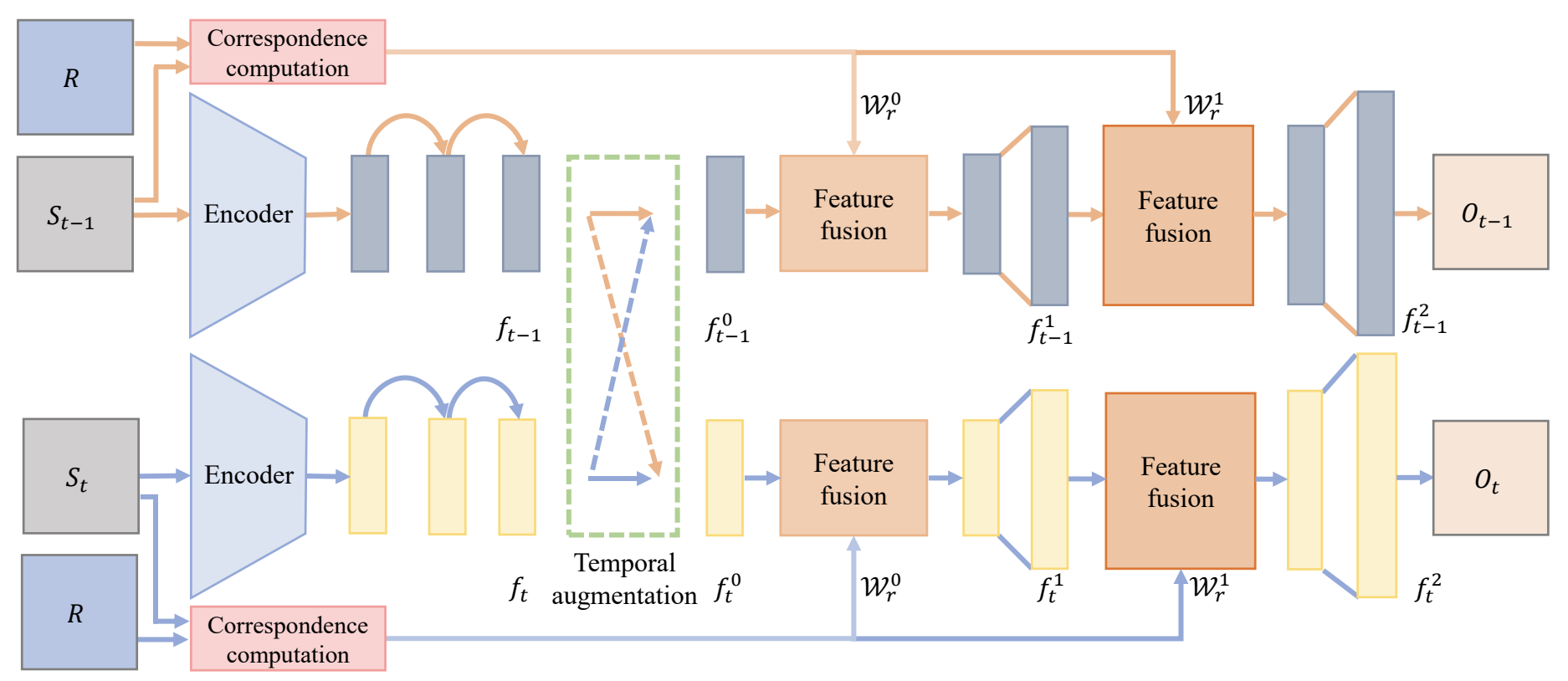 Reference-based Video Colorization with Multi-scale Semantic Fusion and Temporal Augmentation
Reference-based Video Colorization with Multi-scale Semantic Fusion and Temporal Augmentation
Yaxin Liu, Xiaoyan Zhang, Xiaogang Xu#.
IEEE International Conference on Image Processing (ICIP), 2021.[Paper] Code
-
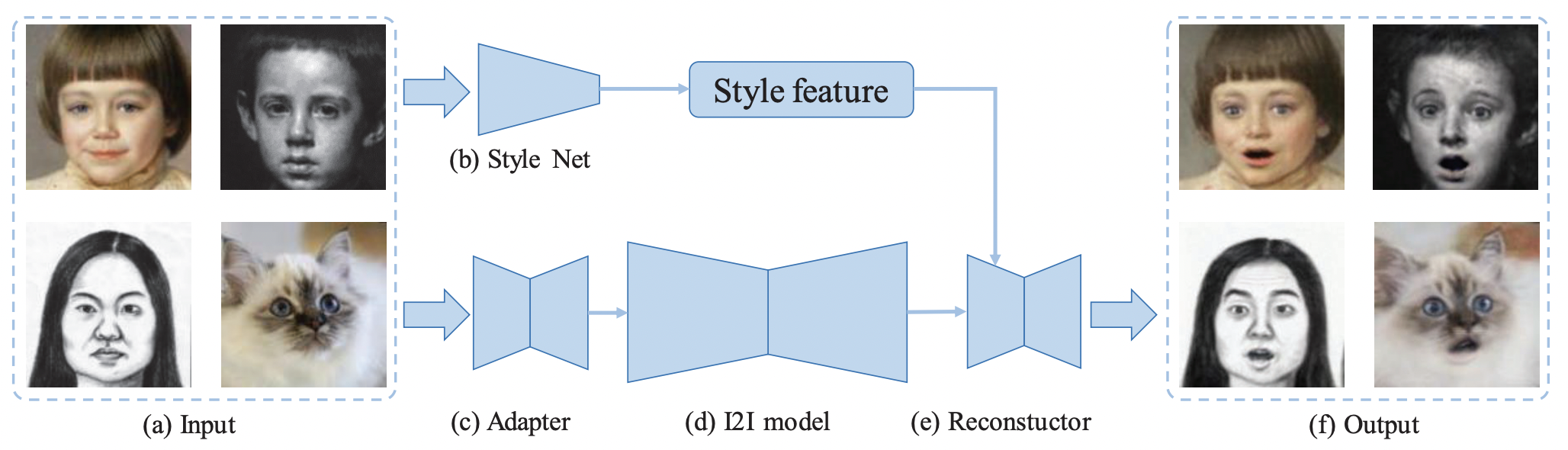 Domain Adaptive Image-to-image Translation
Domain Adaptive Image-to-image Translation
Yingcong Chen, Xiaogang Xu, Jiaya Jia.
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2020 (acceptance rate 22.1% (1470/6656)). -
View Independent Generative Adversarial Network for Novel View Synthesis
Xiaogang Xu, Yingcong Chen, Jiaya Jia.
IEEE International Conference on Computer Vision (ICCV), 2019 Oral (acceptance rate 4.3% (187/4304)).[Paper] Code
-
 Homomorphic Latent Space Interpolation for Unpaired Image-to-image Translation
Homomorphic Latent Space Interpolation for Unpaired Image-to-image Translation
Yingcong Chen, Xiaogang Xu, Zhuotao Tian, Jiaya Jia, Jiaya Jia.
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019 Oral (acceptance rate 5.6% (288/5160)). -
 Ranking Users in Social Networks with Motif-based PageRank
Ranking Users in Social Networks with Motif-based PageRank
Huan Zhao, Xiaogang Xu*, Yangqiu Song, Dik Lun Lee, Zhao Chen, Han Gao.
IEEE Transactions on Knowledge and Data Engineering (TKDE), 2019. -
 Ranking Users in Social Networks with Higher-Order Struct
Ranking Users in Social Networks with Higher-Order Struct
Huan Zhao, Xiaogang Xu*, Yangqiu Song, Dik Lun Lee, Zhao Chen, Han Gao.
AAAI Conference on Artificial Intelligence (AAAI), 2018 (acceptance rate 24.6% (933/3800)). -
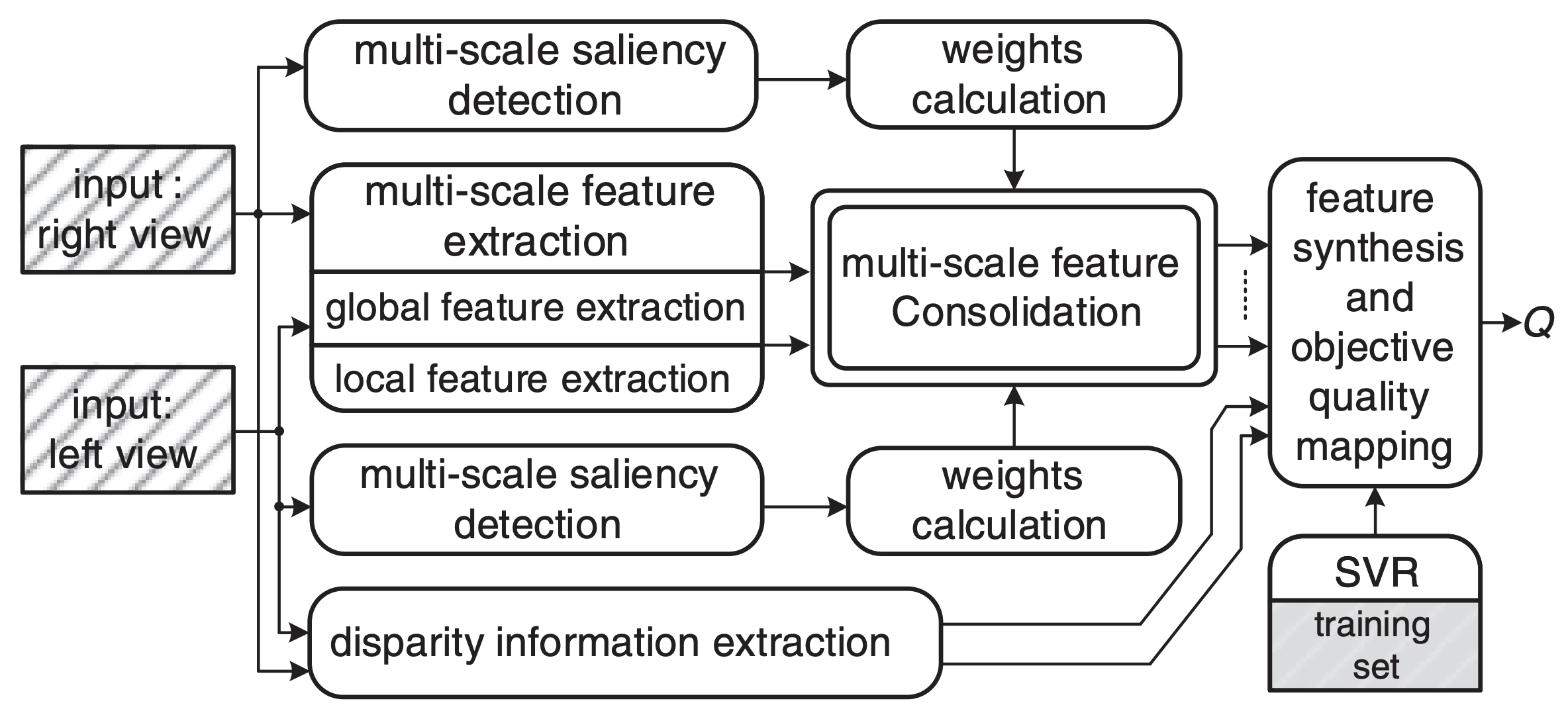 No‑reference stereoscopic image quality assessment based on saliency‑guided binocular feature consolidation
No‑reference stereoscopic image quality assessment based on saliency‑guided binocular feature consolidation
Xiaogang Xu, Yang Zhao, Yong Ding.
Electronics Letters, 2017.
Selective Publications
Low-Light Image Enhancement: Plug-and-Play ImprovementFull Publications
Publications in 2026
Publications in 2025
Publications in 2024
Publications in 2023
Publications in 2022
Publications in 2021
Publications in 2020
Publications in 2019
Publications in 2018
Publications in 2017
Intern Experiences
-
 SmartMore Corporation, Shenzhen, ChinaFeb. 2020 – June. 2022
SmartMore Corporation, Shenzhen, ChinaFeb. 2020 – June. 2022
Research Intern
Advisor: Jiangbo Lu and Nianjuan Jiang
Topic: low-light image/video enhancement and image/video denoising
-
 Microsoft Research, Redmond, WA2021 – 2022
Microsoft Research, Redmond, WA2021 – 2022
Research Intern
Advisor: Vibhav Vineet
Topic: Universal Vision System
-
 Adobe Research, San Jose, CA2020 – 2021
Adobe Research, San Jose, CA2020 – 2021
Research Intern
Advisor: Ning Xu
Topic: Scene‑graph‑based Image Creation
-
 University of Oxford, Oxford, UK2021
University of Oxford, Oxford, UK2021
Visiting Researcher
Advisor: Philip Torr
Topic: Universal Adaptive Data Augmentation and Generative Models for Adversarial Robustness
-
 Youtu Lab, Tencent, Shenzhen, ChinaDec. 2018 – Feb. 2020
Youtu Lab, Tencent, Shenzhen, ChinaDec. 2018 – Feb. 2020
Research Intern
Advisor: Xin Tao and Xiaoyong Shen
Topic: deep learning for image manipulation
-
 KuanDeng, Beijing, ChinaJune. 2018 – Sep. 2018
KuanDeng, Beijing, ChinaJune. 2018 – Sep. 2018
Research Intern
Advisor: Yilun Wang
Topic: high-accuracy segmentation model for open-world roads
-
 Damo academy, AI Lab, Hangzhou, ChinaApr. 2018 – June. 2018
Damo academy, AI Lab, Hangzhou, ChinaApr. 2018 – June. 2018
Research Intern
Advisor: Mingyang Li
Topic: Multi-modality Retrieve for Tmall Genie System
-
 The Network SystEm Security & PrivAcy (NESA) Research Lab, Hangzhou, ChinaSep. 2017 – Apr. 2018
The Network SystEm Security & PrivAcy (NESA) Research Lab, Hangzhou, ChinaSep. 2017 – Apr. 2018
Undergraduate Research Assistant
Advisor: Shouling Ji
Topic: adversarial CAPTCHAs
-
 SenseTime, Hangzhou, ChinaOct. 2017 – Mar. 2018
SenseTime, Hangzhou, ChinaOct. 2017 – Mar. 2018
Research Intern
Advisor: Hanqing Jiang and Guofeng Zhang
Topic: video depth estimation
-
 Knowledge Computation Group at HKUST, Hong KongJuly. 2017 – Oct. 2017
Knowledge Computation Group at HKUST, Hong KongJuly. 2017 – Oct. 2017
Visiting Researcher
Advisor: Yangqiu Song and Huan Zhao
Topic: machine learning for complex graph algorithms
Professional Activities
- Conference Reviewer:
IEEE Conference on Computer Vision and Pattern Recognition (CVPR'18-26, CCF-A).
IEEE International Conference on Computer Vision (ICCV'19-25, CCF-A).
European Conference on Computer Vision (ECCV'20-24, CCF-B).
SIGGRAPH and SIGGRAPH Asia (23-25, CCF-A).
Neural Information Processing Systems (NeurIPS'19-25, CCF-A).
International Conference on Learning Representations (ICLR'20-26).
AAAI Conference on Artificial Intelligence (AAAI'20-26, CCF-A).
International Conference on Machine Learning (ICML'22-25, CCF-A).
IEEE Winter Conference on Applications of Computer Vision (WACV'21-24).
Asian Conference on Computer Vision (ACCV'22, CCF-C).
European Conference on Artificial Intelligence (ECAI'24-25, CCF-B).
Chinese Conference on Pattern Recognition and Computer Vision (PRCV'24, CCF-C).
- Journal Reviewer:
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI, CCF-A).
IEEE Transactions on Circuits and Systems for Video Technology (TCSVT, CCF-B).
IEEE Transactions on Visualization and Computer Graphics (TVCG, CCF-A).
IEEE Transactions on Multimedia (TMM, CCF-B).
IEEE Transactions on Instrumentation and Measurement (TIM, JCR-Q1).
IEEE Transactions on Neural Networks and Learning Systems (TNNLS, CCF-B).
IEEE Signal Processing Letters (SPL, CCF-C).
Computer Vision and Image Understanding (CVIU, CCF-B).
Neural Processing Letters (CCF-C).
International Journal of Computer Vision (IJCV, CCF-A).
International Journal of Human-Computer Interaction (IJHC, CCF-B).
Neurocomputing (CCF-C).
Pattern Recognition (PR, CCF-B).
Knowledge-Based Systems (KBS, CCF-C).
Neural Networks (CCF-B).
IET Image Processing (CCF-C).
Journal of Computer-Aided Design & Computer Graphics (计算机辅助设计与图形学学报, CCF中文A类).
ACM Transactions on Multimedia Computing Communications and Applications (TOMM, CCF-B).
- Program Committee:
AAAI Conference on Artificial Intelligence (AAAI'23-26).
- Area Chair:
International Conference on Machine Learning (ICML'26, CCF-A).
Conference Reviewer
Journal Reviewer
Program Committee
Area Chair
Honors & Awards
-
World’s Top 2% Scientists, published by Stanford University and Elsevier2025
-
Best Demo Honorable Mention in CVPR 2024, for Depth Anything2024
-
Zhejiang Lab Elite Scientist Sponsorship Program, 30 from 3000+ researchers in Zhejiang Lab2024
-
Fourth place in the Image Super Resolution (x4) track in 2024 NTIRE competition2024
-
Large Model Safety Risk Guardrail Theory and Key Technologies (浙江省自然科学基金重大项目, 1,000,000 CNY)2024
-
Cadre member in Zhejiang KunPeng Project (鲲鹏计划, the highest honored research funding in Zhejiang Province)2023
-
Science Fund Program for Excellent Young Scientists at Zhejiang Lab (之江优秀青年科学基金, 1,000,000 CNY)2023
-
2021
-
2018
-
Hong Kong PhD Fellowship2018
-
Outstanding Final-Year Project, ZJU2018
-
Outstanding Graduate, ZJU2018
-
National Scholarship, Ministry of Education of P.R. China2015
-
Title of Outstanding Students, ZJU2015/16/17
-
The scholarship for excellence in research and innovation, ZJU2016/17
-
Zhejiang Provincial Government Scholarship2016
-
China Undergraduate Mathematical Contest in Modeling, National second prize2016
-
Mathematical Contest in Modeling (Honorable Mention), COMAP (U.S.A)2016
Honors & Awards in 2024
Honors & Awards in 2023
Honors & Awards in 2018-2022
Honors & Awards in 2015-2017
Patents
- CN, "A method and symstem for generate text-based adversarial captchas via adding noise in the frequency domain" (一种基于频域加噪的字符对抗验证码生成方法和系统).
- CN, "A method and symstem for generate image-based adversarial captchas via adversarial learning" (一种基于对抗学习的图像对抗验证码生成方法和系统).
- CN, "An efficient inverse pipeline from Log video to RAW video".
- CN, "A noise-consistency-based collection strategy for video denosing pairs".
- CN, "A text-guided image manipulation system via feature alignment".
Teaching
-
ENGG1110: Problem Solving by ProgrammingFall, 2018-2019 in CUHK
-
CSCI4190: Introduction to Social NetworksSpring, 2018-2019 in CUHK
-
ENGG1110: Problem Solving by ProgrammingFall, 2019-2020 in CUHK
-
CSCI3310: Mobile Computing & Application DevelopmentSpring, 2019-2020 in CUHK
-
ENGG1110: Problem Solving by ProgrammingFall, 2020-2021 in CUHK